Job Hunting(职位猎人) - 一款协助找工作的浏览器插件
![]()
为什么要做这个项目
当前国内使用率较高的招聘平台(排名不分先后)分别有 BOSS 直聘,前程无忧,智联招聘,猎聘网,拉勾网,其提供了各个行业的职位招聘信息的展示。但在实际使用过程中发现其展示职位信息的策略对于求职者有诸多不便,包括不仅限于:职位发布时间久远(俗称僵尸岗),不能简单识别普通职位,职位发布时间被隐藏或乱序显示,职位的公司名不是全称,没有职位公司的风险提示。
项目做了什么
为了提高使用这些招聘平台找工作的用户体验,项目会对目标平台网站页面进行增强展示;对出现过的职位进行本地历史快照,跨平台本地检索;对职位数据进行多维度的分析,并以可视化的手段呈现;通过内置的讨论区,对职位进行评论,为职位打上标签等方式进行中立的职位交流;
最近主要改动/新增特性
- 新增服务端
插件
运行截图
招聘/企业信息网站页面
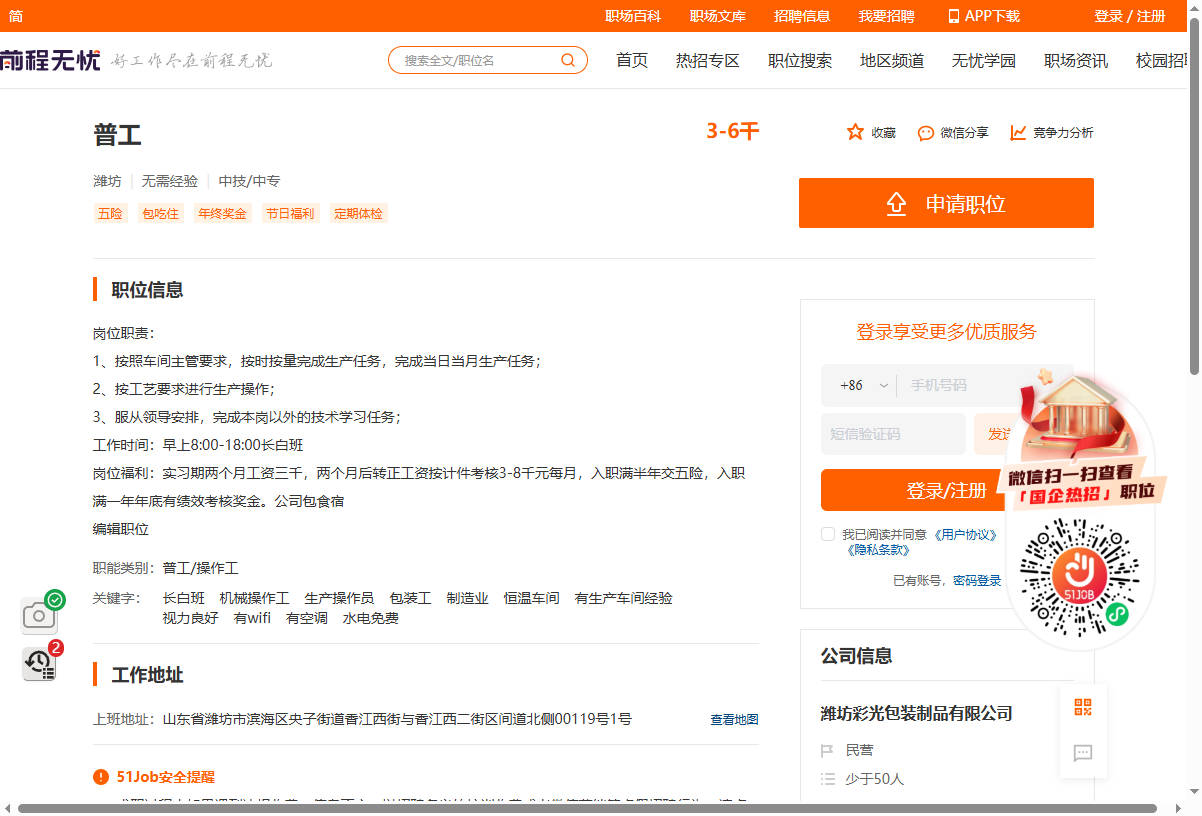
搜索页(前程无忧)

推荐页(BOSS 直聘)
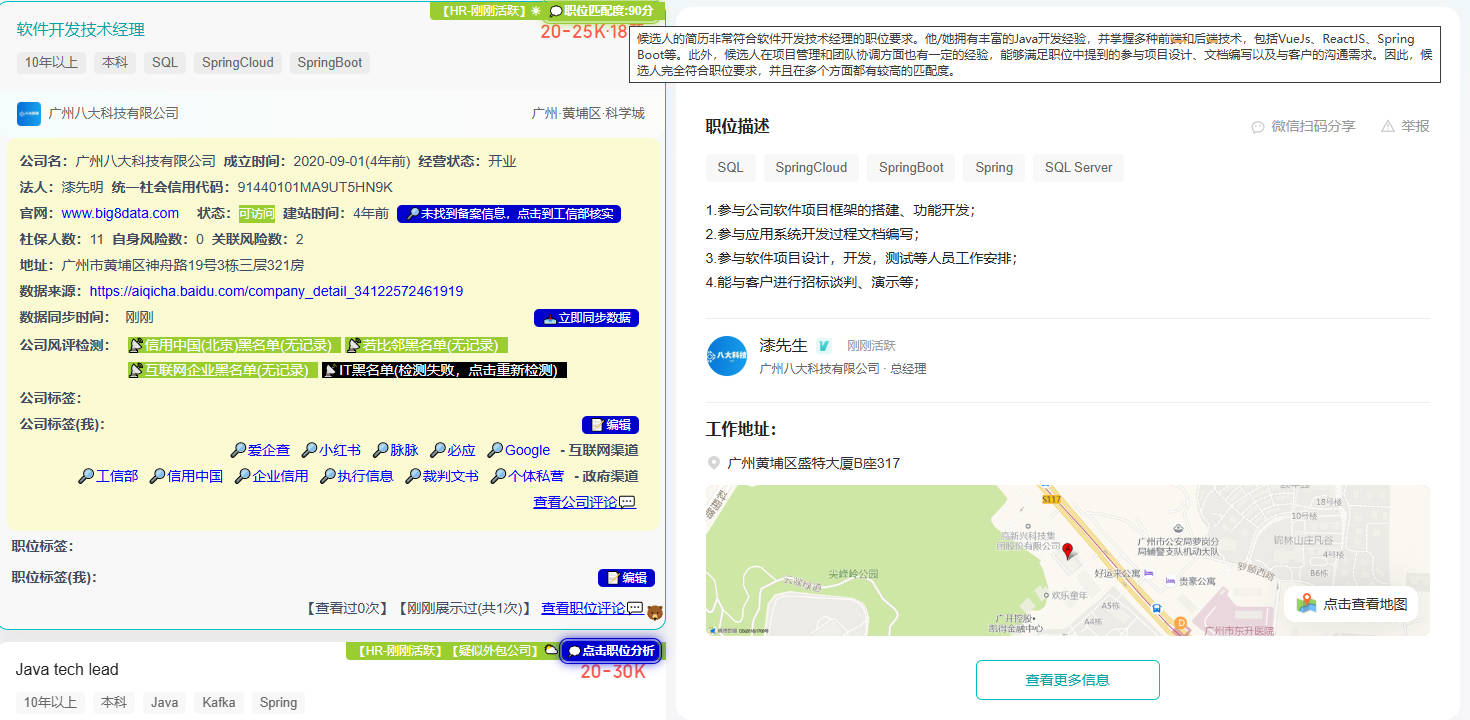
详情页
职位快照
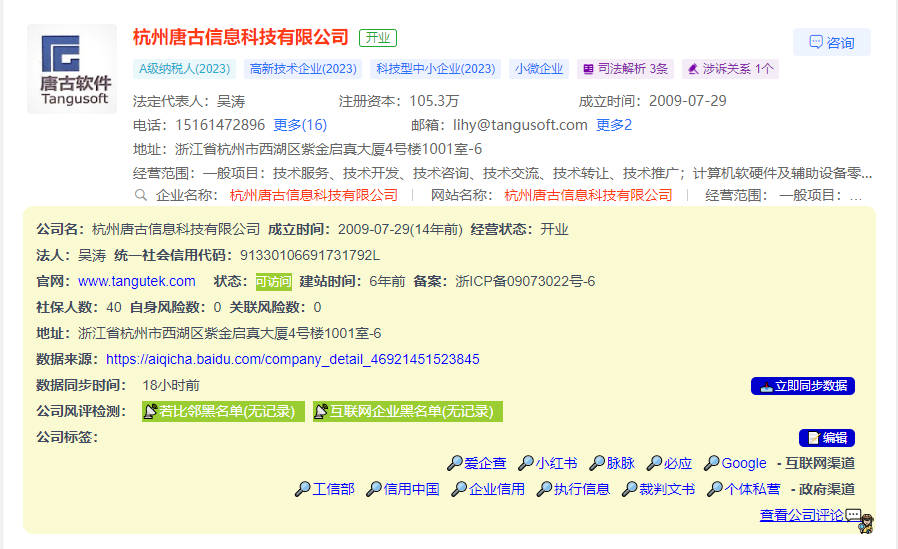
爱企查
管理页面
打开管理页面
管理页面(需点击插件图标打开)
插件安装
插件的开发请跳转到extension 开发目录
- 打开 Release 页 或 直接访问 最新发布
- 点击下载 Assets 下的 job-hunting-extension-chrome-xxx.zip
- 打开浏览器,安装插件,下面是针对不同浏览器的安装步骤
- chrome:地址栏输入 chrome://extensions/,打开开发者模式,将 zip 文件拖进页面里
- edge,地址栏输入 edge://extensions/,打开开发人员模式,将 zip 文件拖进页面里
招聘平台支持列表
| 招聘平台 | 访问地址 | 备注 |
|---|---|---|
| BOSS 直聘 | https://www.zhipin.com/web/geek/jobs | 推荐页/搜索页[账号未登录] |
| https://www.zhipin.com/web/geek/jobs | 推荐页/搜索页[账号已登录] | |
| 前程无忧 | https://we.51job.com/pc/search | 搜索页 |
| 智联招聘 | https://sou.zhaopin.com/ | 搜索页 |
| 拉勾网 | https://www.lagou.com/wn/zhaopin | 搜索页 |
| 猎聘网 | https://www.liepin.com/zhaopin | 搜索页,需点击搜索按钮才有效果 |
| 就业在线 | https://www.jobonline.cn/position | 搜索页 |
| 广东公共求职招聘服务平台 | https://ggfw.hrss.gd.gov.cn/recruitment/internet/main/#/search?type=1 | 搜索页 |
企业搜索平台支持列表
| 企业搜索平台 | 访问地址 | 备注 |
|---|---|---|
| 爱企查 | https://aiqicha.baidu.com/s |
浏览器支持
 Edge |  Chrome |
|---|---|
| last version | last version |
服务端
插件端受限于浏览器本地数据库性能,服务端作为服务端数据处理方案的技术示例,演示了大规模职位数据的存储、检索与分析实现。
首页访问地址:http://localhost:3000/
后台访问地址:http://localhost:3000/login
- 账户/密码: root/Change_Me
注意事项
服务端仅供个人学习与技术研究使用。
- 本服务端为技术学习与研究工具,禁止用于任何商业用途。不推荐公网部署,仅限本地或内网环境使用。
- 使用者在导入或采集数据时须遵守中华人民共和国相关法律法规,包括但不限于《网络安全法》《数据安全法》《个人信息保护法》,不得从事任何侵犯他人合法权益的行为。
- 首次部署后请立即修改默认账户密码(
root/Change_Me),并更换auth_access_token_secret和auth_refresh_token_secret为随机字符串,避免未授权访问与 JWT 伪造。- 对于因使用本服务端而引起的任何法律责任,本项目开发者不承担责任。使用即表示您已阅读并同意免责声明的全部条款。
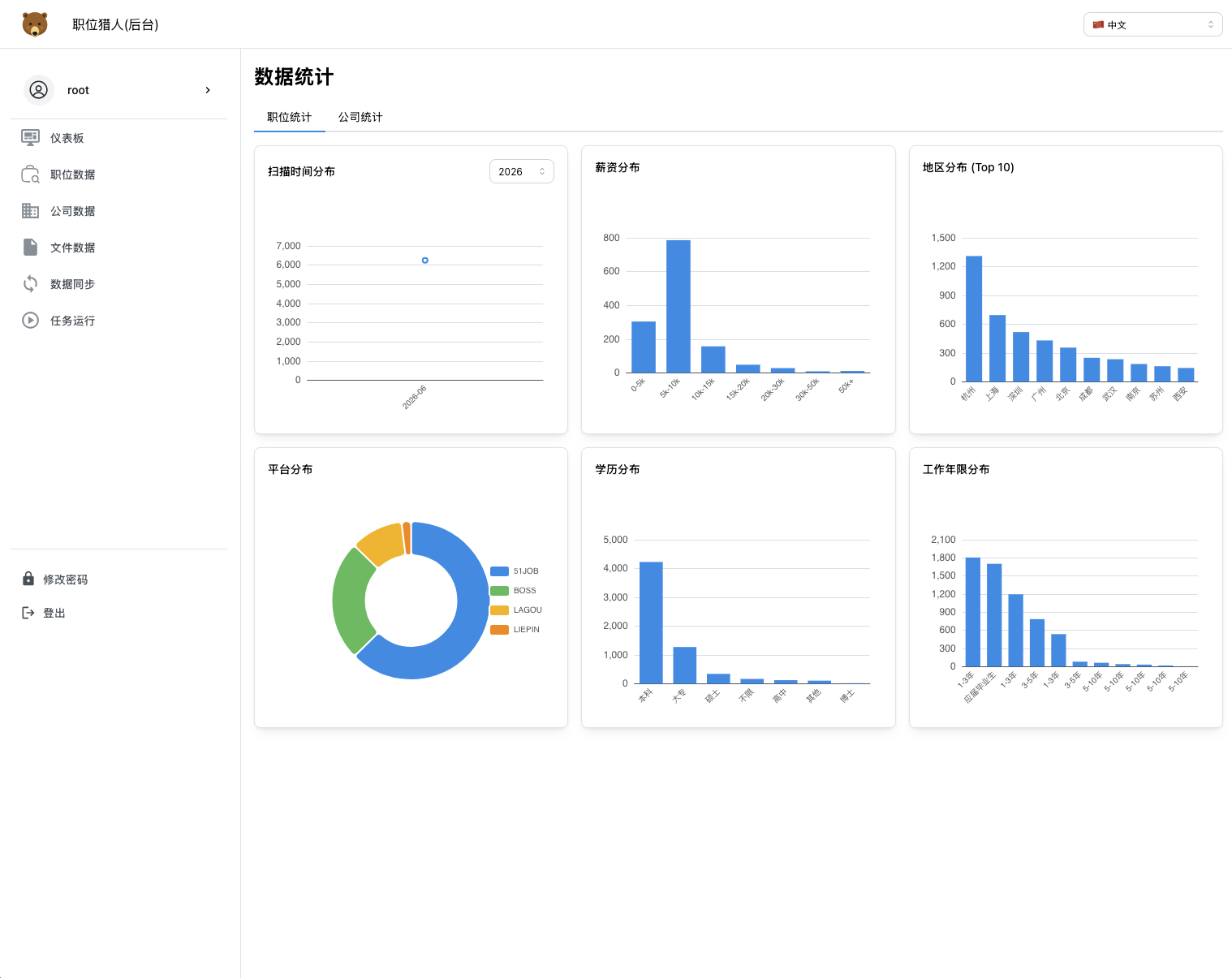
服务端运行截图
仪表板
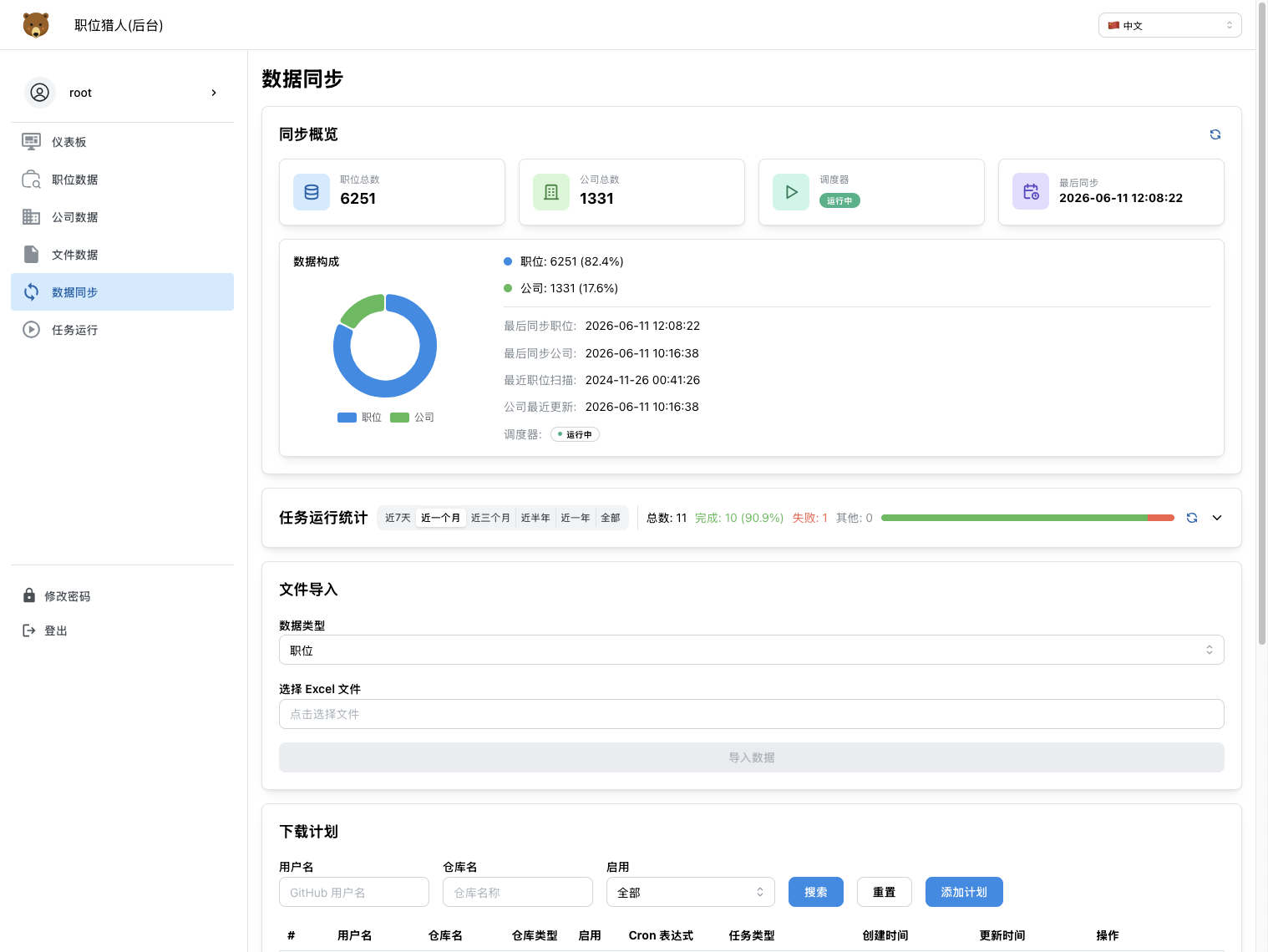
数据同步
教程
快速开始
职位猎人插件
- 打开 Release 页 或 直接访问 最新发布
- 点击下载 Assets 下的 job-hunting-extension-chrome-xxx.zip
- 打开浏览器,安装插件,下面是针对不同浏览器的安装步骤
- chrome:地址栏输入 chrome://extensions/,打开开发者模式,将 zip 文件拖进页面里
- edge,地址栏输入 edge://extensions/,打开开发人员模式,将 zip 文件拖进页面里
- 打开页面
- boss 直聘: https://www.zhipin.com/web/geek/jobs
- 51Job: https://we.51job.com/pc/search
- 智联招聘: https://sou.zhaopin.com/
- 拉钩网:https://www.lagou.com/wn/zhaopin
- 猎聘网: https://www.liepin.com/zhaopin
- 就业在线: https://www.jobonline.cn/position
- 广东公共求职招聘服务平台 https://ggfw.hrss.gd.gov.cn/recruitment/internet/main/#/search?type=1
服务器端
运行服务器
从源码构建
nix develop .#server
cd apps/server
cargo build --release
./target/release/job-hunting-server --config=application.toml
预编译下载
服务器端二进制将随 Release 发布,届时可从 Releases 下载。
可用平台:Linux(amd64/arm64)、macOS(Intel/Apple Silicon/通用)、Windows amd64
配置文件
创建 application.toml:
# 监听地址
address = "0.0.0.0"
port = 3000
# 数据库(SQLite 默认即可)
database_url = "sqlite://db.sqlite?mode=rwc"
# 生产环境务必修改以下三项
auth_access_token_secret = "更换为随机字符串"
auth_refresh_token_secret = "更换为另一随机字符串"
./job-hunting-server-linux-amd64 --config=application.toml
环境变量命名规则:配置字段名转大写 +
JH_前缀,如database_url→JH_DATABASE_URL,address→JH_ADDRESS。也可用-O key=value直接覆盖。
Docker
docker run -e JH_ADDRESS=0.0.0.0 \
-e JH_DATABASE_URL="sqlite:///data/db.sqlite?mode=rwc" \
-v ./data:/data \
-p 127.0.0.1:3000:3000 \
lastsunday/job-hunting:latest
docker-compose(完整部署示例)
仓库中的
docker-compose.yml仅含 PostgreSQL,用于本地开发。以下为完整部署示例。
services:
postgresql:
image: postgres:18.4
environment:
- POSTGRES_PASSWORD=changeme
ports:
- 5432:5432
volumes:
- pgdata:/var/lib/postgresql/data
server:
image: lastsunday/job-hunting:latest
ports:
- 127.0.0.1:3000:3000
environment:
- JH_ADDRESS=0.0.0.0
- JH_DATABASE_URL=postgres://postgres:changeme@postgresql:5432/postgres
depends_on:
- postgresql
volumes:
pgdata:
访问
- 管理后台:http://localhost:3000/login(默认账号
root/Change_Me) - API 文档(Scalar):http://localhost:3000/docs
首次部署后请立即修改默认密码,并更换
auth_access_token_secret和auth_refresh_token_secret为随机字符串(可在配置文件中设置,或通过JH_AUTH_ACCESS_TOKEN_SECRET/JH_AUTH_REFRESH_TOKEN_SECRET环境变量覆盖)。否则持有默认值者可伪造 JWT。
开发
浏览器插件
[!IMPORTANT] 项目根目录: apps/extension
编译
- 安装,编译
pnpm i
pnpm run build
-
打开 chrome,选择加载已解压的扩展程序,选择当前项目的 .output/chrome-mv3 目录
-
打开页面
- boss 直聘: https://www.zhipin.com/web/geek/jobs
- 51Job: https://we.51job.com/pc/search
- 智联招聘: https://sou.zhaopin.com/
- 拉钩网:https://www.lagou.com/wn/zhaopin
- 猎聘网: https://www.liepin.com/zhaopin
- 就业在线: https://www.jobonline.cn/position
- 广东公共求职招聘服务平台 https://ggfw.hrss.gd.gov.cn/recruitment/internet/main/#/search?type=1
开发
-
安装,编译
pnpm i pnpm run dev -
chrome 浏览器打开 chrome://extensions/ 页面
-
点击
加载已解压的扩展程序 -
选择项目中生成的 .output/chrome-mv3-dev 文件夹即可
-
每次保存都会重新编译,扩展程序需要**重新点一次刷新按钮**才生效
测试
深入开发
架构
block
columns 1
招聘网站
桌面浏览器
职位猎人浏览器插件
block
数据同步服务
公司信息查询服务
LLM服务
Oauth服务
BBS服务
end
-
招聘网站
- 支持桌面版的招聘网站版面
- 提供职位信息列表
-
桌面浏览器
- Chrome,Edge
-
职位猎人浏览器插件
-
外部服务
-
数据同步服务
Git- 基础信息
- 职位信息
- 公司信息
- 职位标签
- 公司标签
- 数据源
- 基础信息
-
公司信息查询服务
- 基础信息
- 风评
-
公司评论查询服务
-
LLM 服务
内嵌 LLM(Web llm),远程 LLM- 职位分析
-
Oauth 服务
Github Oauth2 -
BBS 服务
Github Issues API- 讨论区
- 评论(职位,公司)
-
职位猎人浏览器插件
职位展示页面
- 数据获取
- 职位
- 公司
- 数据持久化
- 自定义职位卡片信息
- 职位发布/初见时间
- 公司特性检测(外包,培训机构等...)
- 年龄限制检测
- 职位浏览/展示次数
- 职位匹配度
- HR 活跃状态
- 标签
- 职位
- 公司
- 评论
- 职位
- 公司
- 公司风评检测
- 公司官网
- 可达性检测
- 备案信息检测
后台管理
- 职位搜索
- 列表
- 地图
- 职位浏览历史
- 职位详情快照
- 讨论区
- 数据
- 职位
- 公司
- 标签
- 职位标签
- 公司标签
- 公司评论
- 数据源
- 列表
- 元数据
- 任务
- 统计
- 详情
- 系统
- 设置
- 数据备份
- 数据管理
- 数据导入
- 数据导出
- 数据库
- 概况
- 调试
- 文件
- 设置
核心逻辑
从网站获取数据和渲染额外信息
职位数据
sequenceDiagram
participant browser as 浏览器
participant extension as 插件
autonumber
extension ->> browser: 注册待侦测目标页面
browser ->> browser: 打开职位列表页面
browser ->> extension: 触发侦测目标页面事件
extension ->> browser: 注入脚本(拦截XMLHttpRequest)到目标页面
extension ->> extension: 初始化Extension Bridge
browser ->> extension: 发送职位列表数据
extension ->> extension: 监听查找职位列表界面元素
extension ->> extension: 解析职位列表数据
extension ->> extension: 保存职位信息到持久层
extension ->> extension: 从持久层获取保存的职位信息
extension ->> browser: 在职位项界面上进行自定义职位信息渲染
extension ->> browser: 在职位项界面上进行自定义公司信息界面框架渲染
extension ->> browser: 渲染职位评论框架
opt
browser ->> extension: 获取和渲染公司信息
alt 持久层含有指定未过期的公司信息
extension ->> extension: 从持久层获取保存的公司信息
else
extension ->> extension: 向公司信息服务查询公司信息
extension ->> extension: 保存公司信息到持久层
extension ->> extension: 从持久层获取保存的公司信息
end
extension ->> browser: 渲染自定义公司信息
extension ->> browser: 渲染公司评论框架
opt
browser ->> extension: 获取和渲染公司评论信息
extension ->> browser: 渲染公司评论信息
end
end
opt
browser ->> extension: 获取和渲染职位评论信息
extension ->> browser: 渲染职位评论信息
end
公司数据
sequenceDiagram
participant browser as 浏览器
participant extension as 插件
autonumber
extension ->> browser: 注册待侦测目标页面
browser ->> browser: 打开公司列表页面
browser ->> extension: 触发侦测目标页面事件
extension ->> browser: 注入脚本(拦截XMLHttpRequest)到目标页面
extension ->> extension: 初始化Extension Bridge
browser ->> extension: 发送公司列表数据
extension ->> extension: 监听查找公司列表界面元素
extension ->> extension: 解析公司列表数据
alt 持久层含有指定未过期的公司信息
extension ->> extension: 从持久层获取保存的公司信息
else
extension ->> extension: 向公司信息服务查询公司信息
extension ->> extension: 保存公司信息到持久层
extension ->> extension: 从持久层获取保存的公司信息
end
extension ->> browser: 在公司项界面上进行自定义公司信息渲染
extension ->> browser: 渲染自定义公司信息
extension ->> browser: 渲染公司评论框架
opt
browser ->> extension: 获取和渲染公司评论信息
extension ->> browser: 渲染公司评论信息
end
自定义职位卡片渲染
┌────────────────────────────────────────────────────────────────┐
│ │ Job extra info│
│────────────────────────────────────────────────────────────────│
│ Job info │
│ │
│────────────────────────────────────────────────────────────────│
│ Company info │
│ │
│ │
│ │
│────────────────────────────────────────────────────────────────│
│ Company evaluation checking │
│────────────────────────────────────────────────────────────────│
│ Company tag │
│────────────────────────────────────────────────────────────────│
│ Othre|Company comment| Online company comment│
│────────────────────────────────────────────────────────────────│
│ Job tag │
│────────────────────────────────────────────────────────────────│
│ Job browse statistics === Job Comment│
└────────────────────────────────────────────────────────────────┘
-
监听职位列表元素 ▲
平台 职位列表元素定位 备注 前程无忧 .joblist BOSS 直聘 .rec-job-list 猎聘网 .job-list-box 智联招聘 .positionlist__list 拉勾网 .list__YibNq 就业在线 .position-wrap 广东公共求职招聘服务平台 .ant-list-items -
为职位列表容器设置 flex 布局(使得在不改变 dom 结构的情况下,通过设置 css 的 order 属性来达到改变职位项前后位置)
-
渲染
加载中元素 -
渲染职位额外信息
- 进行年龄限制的检测渲染
- 对职位时间进行处理渲染(初见时间/发布时间)
- Hr 活跃时间渲染
- 职位的公司信息(外包/培训机构)渲染
- 对职位时间进行染色
- 职位分析检测和渲染
-
隐藏
加载中元素 -
修改职位卡片 css 的 order 属性,对职位卡片进行排序
-
渲染底部功能栏
- 渲染 logo
- 公司信息渲染
- 查询公司信息按钮渲染
- 对公司名处理
- 公司详情渲染
- 公司标签渲染(其他人/我)
- 公司风评渲染
- 其他途径查询弹窗渲染
- 在线公司评论按钮渲染
- 职位标签渲染(其他人/我)
- 职位查看和展示次数渲染
-
最终渲染
- 职位评论按钮渲染
- 职位卡片渲染完成标识
内部 API
内部 API 注册与使用
1. Service 注册(worker.js)
const ACTION_FUNCTION = new Map();
export const WorkerBridge = {
ping: function (message, param) {
postSuccessMessage(message, 'pong');
},
};
const { mergeServiceMethod } = useService();
mergeServiceMethod(ACTION_FUNCTION, WorkerBridge);
mergeServiceMethod(ACTION_FUNCTION, DataSourceMetadataService);
2. API 注册(api/index.js)
export const DataSourceMetadataApi = {
dataSourceMetadataSearch: mockFunction,
dataSourceMetadataAddOrUpdate: mockFunction,
dataSourceMetadataBatchAddOrUpdate: mockFunction,
dataSourceMetadataGetById: mockFunction,
dataSourceMetadataGetByIds: mockFunction,
dataSourceMetadataDeleteById: mockFunction,
dataSourceMetadataDeleteByIds: mockFunction,
};
fillBridgeApi({ api: DataSourceMetadataApi });
3. API 使用
[!IMPORTANT] 通过 API 方法来调用 Service 方法
const param = new DataSourceMetadataSearchBO();
param.enable = true;
param.orderByColumn = 'seq';
param.orderBy = 'ASC';
const result = await DataSourceMetadataApi.dataSourceMetadataSearch(param);
约束
- 方法名约定: ClassName+MethodName,如 DataSourceMetadataApi
- ClassName: DataSourceMetadata
- MethodName: Search
- 结果为: dataSourceMetadataSearch
- 方法传入参数类型约定: JSONObject 或其他基本数据类型
- 方法都为 async function
原理
- 利用 JSONObject 的 keys,value 进行 Service 方法的绑定
const fillBridgeApi = ({ api = {} } = {}) => {
const keys = Object.keys(api);
keys.forEach((invokeName) => {
api[invokeName] = async (param) => {
const result = await invoke(invokeName, param);
return result.data;
};
});
return api;
};
- 手动声明进行 Service 方法绑定
export const JobSnapshotApi = {
jobSnapshotDeleteByIds: async function (param) {
const result = await invoke(this.jobSnapshotDeleteByIds.name, param);
return result.data;
},
};
- 利用方法名来定位 Service 和 Service 方法: className+MethodName
内部 API 调用原理
[!IMPORTANT] action = className+MethodName
从 ContentScript 调用
sequenceDiagram
participant Api
participant ContentScript
participant Background
participant Offscreen
participant WebWorker
autonumber
ContentScript ->> Api: 调用Api方法
Api ->> ContentScript: 调用invoke方法,传递action,param
ContentScript ->> ContentScript: 生成callbackId和Promise
ContentScript ->> ContentScript: 关联callbackId和当前生成的Promise
ContentScript ->> Background: 发送Message
alt 如果Background可以处理该Message
Background ->> Background: 处理Message
Background -->> ContentScript: 返回处理后的Message
else
Background ->> Offscreen: 转发Message
Offscreen ->> WebWorker: 转发Message
WebWorker ->> WebWorker: 处理Message
WebWorker -->> Offscreen: 返回处理后的Message
Offscreen -->> Background: 转发处理后的Message
Background -->> ContentScript: 转发处理后的Message
end
ContentScript ->> ContentScript:根据返回Message的callbadkId查找Promise
alt 如果Message含有error
ContentScript ->> Api:调用Promise.reject返回错误
else
ContentScript ->> Api:调用Promise.resolve返回结果
end
从 Background 调用
sequenceDiagram
participant Api
participant Background
participant Offscreen
participant WebWorker
autonumber
Background ->> Api: 调用Api方法
Api ->> Background: 调用invoke方法,传递action,param
Background ->> Background: 生成callbackId和Promise
Background ->> Background: 关联callbackId和当前生成的Promise
Background ->> Offscreen: 发送Message
Offscreen ->> WebWorker: 转发Message
WebWorker ->> WebWorker: 处理Message
WebWorker -->> Offscreen: 返回处理后的Message
Offscreen -->> Background: 转发处理后的Message
Background ->> Background:根据返回Message的callbadkId查找Promise
alt 如果Message含有error
Background ->> Api:调用Promise.reject返回错误
else
Background ->> Api:调用Promise.resolve返回结果
end
从 WebWorker 调用
[!IMPORTANT]
- Webworker 发起的 Api 调用不会经过 ContentScript,Background,Offscreen 这些模块的处理流程
- 调用的方法仅限于 Github Api (仅执行网络访问)
对大 Message 传递的处理
[!IMPORTANT]
内嵌数据库
SQL Class
---
title: Database
---
classDiagram
class Database
Database: +initDb$({ dataDir } = {})
Database: +getOne$(sql, bind, obj, { connection = null } = {})
Database: +getAll$(sql, bind, obj, { connection = null } = {})
Database: +batchInsert$(obj, tableName, params, { overrideCreateDatetime = false, overrideUpdateDatetime = false, connection = null } = {})
Database: +batchInsertOrReplace$(obj, tableName, tableIdColumn, params, { replace = true, overrideCreateDatetime = false, overrideUpdateDatetime = false, connection = null } = {})
Database: +one$(entity, tableName, idColumn, id, { connection = null } = {})
Database: +all$(entity, tableName, orderBy, { connection = null } = {})
Database: +batchGet$(obj, tableName, idColumnName, ids, { connection = null } = {})
Database: +del$(tableName, idColumn, id, { otherCondition = null, connection = null } = {})
Database: +batchDel$(tableName, idColumn, ids, { otherCondition = null, connection = null } = {})
Database: +search$(entity, tableName, param, whereConditionFunction, { connection = null } = {})
Database: +searchCount$(entity, tableName, param, whereConditionFunction, { connection = null } = {})
Database: +sort$(tableName, idColumnName, param, { connection = null } = {})
Database: +innerInit({ dataDir } = {})
Database: +dbExport(message, param)
Database: +dbImport(message, param)
Database: +dbClose(message, param)
Database: +dbDelete(message, param)
Database: +dbSize(message, param)
Database: +dbSchemaVersion(message, param)
Database: +dbExec(message, param)
Database: +dbGetAllTableName(message, param)
class BaseService
BaseService: +constructor(tableName, tableIdColumn, entityClassCreateFunction, searchDTOCreateFunction, whereConditionFunction)
BaseService: +search(message, param, { detailInjectAsyncCallback = null, entityClassCreateFunction = null } = {})
BaseService: +count(message, param)
BaseService: +getOne(message, param, column)
BaseService: +getById(message, param)
BaseService: +getByIds(message, param)
BaseService: +addOrUpdate(message, param)
BaseService: +deleteById(message, id, column)
BaseService: +deleteByIds(message, ids, column)
BaseService: #_search(param, { detailInjectAsyncCallback = null, connection = null, entityClassCreateFunction = null } = {})
BaseService: #_count()
BaseService: #_getOne(param, column)
BaseService: #_getById(param, { connection = null } = {})
BaseService: #_getByIds(param, { connection = null } = {})
BaseService: #_deleteById(id, column, { otherCondition, connection = null } = {})
BaseService: #_deleteByIds(ids, column, { connection = null, otherCondition = null } = {})
BaseService: #_updateByIds(ids, column, { otherCondition })
BaseService: #_addOrUpdate(param, { overrideUpdateDatetime = false, overrideCreateDatetime = false, connection = null } = {})
BaseService: #_batchAddOrUpdate(params, { connection = null, overrideCreateDatetime = false, overrideUpdateDatetime = false, genIdFunction = null, entityClassCreateFunction = null } = {})
class BaseBridgeService
BaseBridgeService: +constructor(baseServiceInstance, serviceName)
BaseBridgeService: +getMethodName(name)
BaseBridgeService: +getMethodNameMap()
BaseBridgeService: +addServiceMethod$({ bridgeService = null, methodName = null, methodFunction = async ({ param = null } = {}) => { } } = {})
BaseBridgeService: +addTransactionServiceMethod$({ bridgeService = null, methodName = null, methodFunction = async ({ param = null, tx = null } = {}) => { } } = {})
BaseBridgeService: +fillBaseServiceMethod$({ bridgeService = null, overrideUpdateDatetime = false, overrideCreateDatetime = false } = {})
BaseService ..> Database
BaseBridgeService ..> BaseService
Service 实现
import { DataSourceMetadataSearchBO } from '@/common/data/bo/dataSourceMetadataSearchBO';
import { DataSourceMetadata } from '@/common/data/domain/dataSourceMetadata';
import BaseBridgeService, { fillBaseServiceMethod } from './baseBridgeService';
import { BaseService } from './baseService';
import {
genEqValueConditionSql,
genInTextSql,
genLikeSql,
genRangeDatetimeConditionSql,
} from './sqlUtil';
const TABLE_NAME = 'data_source_metadata';
const TABLE_ID_COLUMN = 'id';
const SERVICE_NAME = 'dataSourceMetadata';
export const SERVICE_INSTANCE = new BaseService(
TABLE_NAME,
TABLE_ID_COLUMN,
() => {
return new DataSourceMetadata();
},
() => {
return new DataSourceMetadataSearchBO();
},
(param) => {
let whereCondition = ''.concat(
genInTextSql(param.id, 'id'),
genLikeSql(param.name, 'name'),
genEqValueConditionSql(param.enable, 'enable'),
genInTextSql(param.type, 'type'),
genEqValueConditionSql(param.autoUpdateEnable, 'auto_update_enable'),
genRangeDatetimeConditionSql(
param.startDatetimeForCreate,
param.endDatetimeForCreate,
'create_datetime'
),
genRangeDatetimeConditionSql(
param.startDatetimeForUpdate,
param.endDatetimeForUpdate,
'update_datetime'
)
);
return whereCondition;
}
);
const DataSourceMetadataService = new BaseBridgeService(
SERVICE_INSTANCE,
SERVICE_NAME
);
fillBaseServiceMethod({
bridgeService: DataSourceMetadataService,
overrideCreateDatetime: true,
overrideUpdateDatetime: true,
});
export default DataSourceMetadataService;
ORM 机制
- 例子
const company = new Company();
await CompanyApi.addOrUpdateCompany(company);
//companyService
const SERVICE_INSTANCE = new BaseService(
'company',
'company_id',
() => {
return new Company();
},
() => {
return new SearchCompanyDTO();
},
null
);
export const CompanyService = {
addOrUpdateCompany: async function (message, param) {
try {
await SERVICE_INSTANCE._batchAddOrUpdate([param]);
postSuccessMessage(message, {});
} catch (e) {
postErrorMessage(
message,
'[worker] addOrUpdateCompany error : ' + e.message
);
}
},
};
-
当前实现的特性
- 根据 JSONObject 进行 SQL 查询,新增,更新,删除
-
底层原理
- 利用 JSONObject 的 keys,value 来识别列名,字段类型和内容。通过此来进行 SQL 的生成和返回结果 JSONObject 的生成
- JSONObject 属性名采用小驼峰命名法(lowerCamelCase)
- 表字段名采用下划线命名法(Snake Case)
- SQL 插入字段的值位置采用下标定位的方式,如$1
- 分页采用 LIMIT,OFFSET
Schema Changes
const changelogList = getChangeLogList();
let oldVersion = 0;
const newVersion = changelogList.length;
try {
await db.transaction(async (tx) => {
const SQL_CREATE_TABLE_VERSION = `
CREATE TABLE IF NOT EXISTS version(
num INTEGER
)
`;
await tx.exec(SQL_CREATE_TABLE_VERSION);
const SQL_QUERY_VERSION = 'SELECT num FROM version';
const result = await tx.query(SQL_QUERY_VERSION);
const rows = result.rows;
if (rows.length > 0) {
oldVersion = rows[0].num;
} else {
const SQL_INSERT_VERSION = `INSERT INTO version(num) values($1)`;
await tx.query(SQL_INSERT_VERSION, [0]);
}
infoLog(
'[DB] schema oldVersion = ' + oldVersion + ', newVersion = ' + newVersion
);
if (newVersion > oldVersion) {
infoLog('[DB] schema upgrade start');
for (let i = oldVersion; i < newVersion; i++) {
const currentVersion = i + 1;
const changelog = changelogList[i];
const sqlList = changelog.getSqlList();
infoLog(
'[DB] schema upgrade changelog version = ' +
currentVersion +
', sql total = ' +
sqlList.length
);
for (let seq = 0; seq < sqlList.length; seq++) {
infoLog(
'[DB] schema upgrade changelog version = ' +
currentVersion +
', execute sql = ' +
(seq + 1) +
'/' +
sqlList.length
);
const sql = sqlList[seq];
await tx.exec(sql);
}
}
const SQL_UPDATE_VERSION = `UPDATE version SET num = $1`;
await tx.query(SQL_UPDATE_VERSION, [newVersion]);
infoLog('[DB] schema upgrade finish to version = ' + newVersion);
infoLog('[DB] current schema version = ' + newVersion);
} else {
infoLog('[DB] skip schema upgrade');
infoLog('[DB] current schema version = ' + oldVersion);
}
});
} catch (e) {
errorLog('[DB] schema upgrade fail,' + e.message);
}
-
ChangeLog 文件
-
文件格式: ChangeLog+V+版本号 = ChangeLogVxxx.js
-
例子
export class ChangeLogV1 extends ChangeLog { getSqlList() { let sqlList = [ SQL_CREATE_TABLE_JOB, SQL_CREATE_TABLE_JOB_BROWSE_HISTORY, ]; return sqlList; } }
-
-
ChangeLog 执行规则
- 将需要执行的 ChangeLog 存放到列表中
- 开启事务,以确保 ChangeLog 的执行的原子性
- 通过计算 ChangeLog 列表的总数与当前数据库版本号(版本号为上一次执行 ChangLog 的数量)进行对比计算,来获取当前需要执行的 ChangeLog
- 执行完成后,更新数据库版本号(版本号即为已执行 ChangeLog 的数量)
备份
[!IMPORTANT] 当前使用 pglite dump 备份大量数据的数据库会出错
TODO
内部任务系统
---
title: Task System
---
sequenceDiagram
participant Service
participant Database
participant GitHubApi
participant GitService
Note right of Service: 计算和保存下载和上传任务
Service ->> Database: 获取数据同步配置
Database -->> Service: 返回数据同步配置
opt if 开启私有数据同步
Service ->> Database: 获取用户信息
Database -->> Service: 返回用户信息
Service ->> Service: 获取私有数据上传任务类型
opt if 需要同步私有的数据
Service ->> Service: 获取私有数据仓库名
Service ->> GitHubApi: 尝试根据用户名和仓库名创建私有数据仓库
loop 私有数据上传任务类型
rect rgb(191, 223, 255)
Note right of Service: 计算并保存上传任务
Service ->> Database: 根据用户名,仓库名获取指定任务类型最近上传任务截至时间
Database -->> Service: 返回最近上传任务截至时间
opt if 最近上传任务截至时间不为今天
Service ->> GitService: 根据用户名,仓库名和获取指定任务类型最近上传文件时间
GitService -->> Service: 返回最近上传文件时间
Service ->> Service: 在最近上传任务截至时间和最近上传文件时间取最小值,作为任务开始时间
Service ->> Database: 根据用户名,仓库名,任务类型,任务开始时间,任务结束时间(今天)保存任务记录
end
end
end
Service ->> Service: 获取私有数据下载任务类型
Service ->> Service: 将私有数据下载任务保存到下载列表
end
end
alt if 是否开启公开数据同步
Service ->> Database: 获取用户信息
Database -->> Service: 返回用户信息
Service ->> Service: 获取公开数据上传任务类型
opt if 有需要同步公开的数据
Service ->> Service: 获取公开数据仓库名
Service ->> GitHubApi: 尝试根据用户名和仓库名创建公开数据仓库
loop 公开数据上传任务类型
rect rgb(191, 223, 255)
Note right of Service: 计算并保存上传任务
end
end
Service ->> Service: 获取公开数据下载任务类型
Service ->> Service: 将公开数据下载任务保存到下载列表
end
end
Service ->> Database: 获取数据共享伙伴列表
Database -->> Service: 返回数据共享伙伴列表
Service ->> Service: 将数据共享伙伴数据的下载任务保存到下载列表
loop 下载列表
Service ->> Service: 根据下载列表获取伙伴信息
Service ->> Service: 根据下载列表获取下载任务类型
loop 下载任务类型
rect rgb(191, 255, 223)
Note right of Service: 计算并保存下载任务
Service ->> GitService: 根据任务类型或文件名查询日期目录列表
GitService -->> Service: 返回日期目录列表
Service ->> Service: 根据下载历史文件保留天数和当前日期过滤和升序日期列表,获得仓库文件日期列表
Service ->> Service: 根据仓库文件日期列表,获取开始时间(列表中最小时间)和结束时间(列表中最大时间)
Service ->> Database: 根据开始时间和结束时间查询指定类型的下载任务列表
Database -->> Service: 返回下载任务列表
Service ->> Service: 根据仓库文件日期列表和下载任务列表的日期计算得出本地缺失日期列表
Service ->> Database: 根据本地缺失日期列表,新增指定类型的下载任务
end
end
end
Service ->> Database: 获取数据源元数据自动更新列表
Database -->> Service: 返回数据源元数据自动更新列表
loop 数据源元数据自动更新列表
rect rgb(255, 223,191)
Note right of Service: 计算并保存元数据下载任务
Service ->> Database: 根据任务类型编号获取最近下载任务列表
Database -->> Service: 返回下载任务列表
opt if 任务列表中含有非今天未完成的任务
Service ->> Database: 将未完成的任务状态设置为取消
end
opt if 任务列表中没有今天未完成的任务
Service ->> Database: 新增数据源元数据下载任务
end
end
end
Note right of Service: 执行下载和上传任务
Service ->> Database: 查询需要执行的任务
Database -->> Service: 返回需要执行的任务
Service ->> Service: 执行查询到的需要执行的任务
Note right of Service: 执行定时任务
Service ->> Database: 查询已合并但未删除的文件
Database -->> Service: 返回已合并但未删除的文件
Service ->> Service: 根据历史文件保留数量和最大历史文件保留容量计算需要删除的文件列表
Service ->> Database: 根据需要删除的文件列表删除文件
任务状态图
---
title: Task state
---
stateDiagram-v2
[*] --> READY
READY --> RUNNING
READY --> CANCEL
RUNNING --> FINISHED
RUNNING --> FINISHED_BUT_ERROR
RUNNING --> ERROR
RUNNING --> CANCEL
FINISHED --> [*]
FINISHED_BUT_ERROR --> [*]
ERROR --> [*]
CANCEL --> [*]
数据关系图
---
title: Task ER
---
erDiagram
task ||--|| task_data_upload: owns
task {
string(255) id PK "编号"
string(255) type "任务类型"
string(255) data_id FK "任务详情编号"
string(255) status "任务状态"
string error_reason "错误原因"
int cost_time "耗时"
int retry_count "重试次数"
datetime create_datetime "创建时间"
datetime update_datetime "更新时间"
}
task_data_upload {
string(255) id PK "编号"
string(255) type "任务类型"
string(255) username "用户名"
string(255) reponame "仓库名"
datetime start_datetime "开始时间"
datetime end_datetime "结束时间"
int data_count "数据量"
int data_page_num "页数"
int data_page_size "页大小"
datetime create_datetime "创建时间"
datetime update_datetime "更新时间"
}
task ||--|| task_data_download: owns
task_data_download {
string(255) id PK "编号"
string(255) type "任务类型"
string(255) username "用户名"
string(255) reponame "仓库名"
datetime datetime "日期"
int seq "序号"
datetime create_datetime "创建时间"
datetime update_datetime "更新时间"
string(255) type_id "类型标识,用于识别特定文件"
json config "配置"
string(255) data_id FK "文件编号"
}
task ||--|| task_data_merge: owns
task_data_merge {
string(255) id PK "编号"
string(255) type "任务类型"
string(255) username "用户名"
string(255) reponame "仓库名"
datetime datetime "日期"
string(255) data_id FK "文件编号"
int data_count "数据量"
int data_page_num "页数"
int data_page_size "页大小"
datetime create_datetime "创建时间"
datetime update_datetime "更新时间"
string(255) type_id "类型标识,用于识别特定文件"
json config "配置"
}
task_data_merge |o--|| file: has
file {
string(255) id PK "编号"
string(255) name "文件名"
string(255) sha "散列值"
string(255) encoding "编码"
string content "文件内容"
int size "文件尺寸"
string type "文件类型"
is_delete boolean "是否刪除"
datetime create_datetime "创建时间"
datetime update_datetime "更新时间"
}
任务类型
export const TASK_TYPE_JOB_DATA_UPLOAD = 'JOB_DATA_UPLOAD';
export const TASK_TYPE_JOB_DATA_DOWNLOAD = 'JOB_DATA_DOWNLOAD';
export const TASK_TYPE_JOB_DATA_MERGE = 'JOB_DATA_MERGE';
export const TASK_TYPE_COMPANY_DATA_UPLOAD = 'COMPANY_DATA_UPLOAD';
export const TASK_TYPE_COMPANY_DATA_DOWNLOAD = 'COMPANY_DATA_DOWNLOAD';
export const TASK_TYPE_COMPANY_DATA_MERGE = 'COMPANY_DATA_MERGE';
export const TASK_TYPE_COMPANY_TAG_DATA_UPLOAD = 'COMPANY_TAG_DATA_UPLOAD';
export const TASK_TYPE_COMPANY_TAG_DATA_DOWNLOAD = 'COMPANY_TAG_DATA_DOWNLOAD';
export const TASK_TYPE_COMPANY_TAG_DATA_MERGE = 'COMPANY_TAG_DATA_MERGE';
export const TASK_TYPE_JOB_TAG_DATA_UPLOAD = 'JOB_TAG_DATA_UPLOAD';
export const TASK_TYPE_JOB_TAG_DATA_DOWNLOAD = 'JOB_TAG_DATA_DOWNLOAD';
export const TASK_TYPE_JOB_TAG_DATA_MERGE = 'JOB_TAG_DATA_MERGE';
export const TASK_TYPE_JOB_PUBLIC_DATA_UPLOAD = 'JOB_PUBLIC_DATA_UPLOAD';
export const TASK_TYPE_JOB_PUBLIC_DATA_DOWNLOAD = 'JOB_PUBLIC_DATA_DOWNLOAD';
export const TASK_TYPE_JOB_PUBLIC_DATA_MERGE = 'JOB_PUBLIC_DATA_MERGE';
export const TASK_TYPE_METADATA_DATA_DOWNLOAD = 'METADATA_DATA_DOWNLOAD';
export const TASK_TYPE_METADATA_DATA_MERGE = 'METADATA_DATA_MERGE';
export const TASK_TYPE_COMPANY_COMMENT_DATA_DOWNLOAD =
'COMPANY_COMMENT_DATA_DOWNLOAD';
export const TASK_TYPE_COMPANY_COMMENT_DATA_MERGE =
'COMPANY_COMMENT_DATA_MERGE';
数据同步
数据仓库文件结构
├── YYYY //年份,格式YYYY
│ └── MM-DD //月日,格式MM-DD
│ ├─── company.zip
│ ├─── job.zip
│ ├─── job_tag.zip
│ ├─── company_tag.zip
Git 读取数据仓库文件结构
sequenceDiagram
participant GitService
participant GitServer
GitService ->> GitServer: 发送ls-refs请求
GitServer -->> GitService: 返回refs
GitService ->> GitService: 根据refs获取commitHash
GitService ->> GitServer: 根据commitHash获取treesIdx
GitServer -->> GitService: 返回treesIdx
GitService ->> GitServer: 根据treesIdx遍历仓库目录
GitServer -->> GitService: 返回仓库目录
GitService -->> GitService: 根据仓库目录过滤符合日期目录的指定文件的文件列表
数据合并文件
-
文件格式: excel
-
文件内容格式
字段名 字段类型 备注 编号 string 记录唯一标识 xxx xxx __VERSION_int 版本号,如果该字段不存在,则会被认为第 0 版 -
版本识别规则
- 通过版本号字段读取文件的文件字段列表
- 根据文件字段列表识别文件是否合法
数据递增规则
-
以记录创建时间为数据增量规则
-
各数据格式增量更新规则字段
-
职位
createDatetimeupdateDatetimeisFullCompanyName
-
职位公开数据
createDatetime
-
职位快照
updateDatetime
-
职位标签
未正确实现覆盖更新
updateDatetime
-
公司
sourceRefreshDatetime
-
公司标签
未正确实现覆盖更新
updateDatetime
-
公司评论
createDatetime
-
各数据类型版本
职位
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 职位自编号 | string | 0 | |
| 发布平台 | string | 0 | |
| 职位访问地址 | string | 0 | |
| 职位 | string | 0 | |
| 公司 | string | 0 | |
| 公司是否为全称 | bool | 0 | |
| 地区 | string | 0 | |
| 地址 | string | 0 | |
| 经度 | number | 0 | |
| 纬度 | number | 0 | |
| 职位描述 | string | 0 | |
| 学历 | string | 0 | |
| 所需经验 | string | 0 | |
| 技能 | string | 1 | |
| 福利 | string | 1 | |
| 最低薪资 | number | 0 | |
| 最高薪资 | number | 0 | |
| 几薪 | number | 0 | |
| 首次发布时间 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 招聘人 | string | 0 | |
| 招聘公司 | string | 0 | |
| 招聘者职位 | string | 0 | |
| 首次扫描日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 记录更新日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
职位标签
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 职位编号 | string | 0 | |
| 标签 | string | 0 | |
| 记录更新日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
职位公开数据
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 职位自编号 | string | 0 | |
| 首次扫描日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 记录更新日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
职位快照
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 编号 | string | 0 | |
| 职位编号 | string | 0 | |
| 职位链接 | string | 0 | |
| 内容 | string | 0 | |
| 招聘平台 | string | 0 | |
| 创建日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 更新日期 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
公司
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 公司 | string | 0 | |
| 公司描述 | string | 0 | |
| 成立时间 | string | 0 | |
| 经营状态 | string | 0 | |
| 法人 | string | 0 | |
| 统一社会信用代码 | string | 0 | |
| 官网 | string | 0 | |
| 社保人数 | number | 0 | |
| 自身风险数 | number | 0 | |
| 关联风险数 | number | 0 | |
| 地址 | string | 0 | |
| 经营范围 | string | 0 | |
| 纳税人识别号 | string | 0 | |
| 所属行业 | string | 0 | |
| 工商注册号 | string | 0 | |
| 经度 | number | 0 | |
| 纬度 | number | 0 | |
| 注册资本 | string | 2 | |
| 注册资本货币 | string | 2 | |
| 数据来源地址 | string | 0 | |
| 数据来源平台 | string | 0 | |
| 数据来源记录编号 | string | 0 | |
| 数据来源更新时间 | datetime | 0 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 记录创建日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 记录更新日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
公司标签
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 公司 | string | 0 | |
| 标签 | string | 0 | |
| 记录更新日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
公司评论
| 字段 | 类型 | 生效版本 | 格式 |
|---|---|---|---|
| 公司 | string | 0 | |
| 评论 | string | 0 | |
| 情感 | string | 1 | |
| 数据集 | string | 1 | |
| 创建日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
| 更新日期 | datetime | 1 | rfc3339/yyyy-MM-dd HH:mm:ss |
数据导入与导出
[!IMPORTANT] 数据导入逻辑与数据同步逻辑一样
- 数据拆分导出
Oauth
Github Oauth2 流程
sequenceDiagram participant ContentScript participant Background participant GithubWebsite participant GithubServer ContentScript ->> Background: authOauth2Login activate GithubWebsite Background ->> GithubWebsite: chrome.tabs.create Note over GithubWebsite: https://github.com/login/oauth/authorize?client_id= GithubWebsite ->> GithubWebsite: github login GithubWebsite ->> GithubWebsite: redirect to callback url Note over GithubWebsite: https://github.com/lastsunday/job-hunting-github-app/blob/main/INSTALL?code= GithubWebsite -->> Background: notify url with code Background ->> Background: chrome.tabs.onUpdated Background ->> GithubServer: http request access_token Note over GithubWebsite: https://github.com/login/oauth/access_token?client_id=&client_secret=&code= GithubServer -->> Background: return oauth info Background ->> GithubWebsite: chrome.tabs.remove deactivate GithubWebsite
BBS 系统
-
采用 Github Issues 作为服务端
-
地区选择实现原理
-
利用标题作为搜索字段
-
targetId = sha256 地区名: sha256(省)-sha256(市)-sha256(区)
search(query:"${targetId} in:title sort:created-desc is:issue is:open repo:${GITHUB_APP_REPO}", type: ISSUE, first: ${first ?? null}, after: ${after ? "\"" + after + "\"" : null},last:${last ?? null},before:${before ? "\"" + before + "\"" : null})
-
-
使用的 Github API
- HQL 查询(可查询 Issues): https://api.github.com/graphql
- 新增 Issues: POST https://api.github.com/repos/lastsunday/job-hunting-github-app/issues
- 查询 Issues Comment: GET https://api.github.com/repos/lastsunday/job-hunting-github-app/issues/${issueNumber}/comments?per_page=${pageSize}&page=${pageNum}
- 新增 Issues Comment: POST https://api.github.com/repos/lastsunday/job-hunting-github-app/issues/${issueNumber}/comments
自动化
- 采用 puppeteer 类库在 debug 模式下运行
- 当前用于自动浏览职位页面
LLM
-
外部 LLM
-
内嵌 LLM
职位分析组件
[!IMPORTANT] 项目根目录: libs/analysis
编译
pnpm exec nx run analysis:build
文档
pnpm exec nx run analysis:storybook
服务器端
服务器端是一个基于 Axum 的 Rust Web 服务,提供 REST API 和后台任务调度能力。
核心功能
- REST API: 职位/公司数据 CRUD、搜索、分页排序
- 认证授权: JWT(access token + refresh token,HS256)
- OpenAPI 文档: 基于 utoipa + Scalar UI,访问
/docs - 数据同步: 定时从远程仓库拉取数据,解析并合并入库
- 任务调度: 基于 cron 表达式的任务计划系统,支持失败重试
- 静态文件服务: 内嵌管理后台 SPA(
server-ui)
Crate 结构
graph TD
binary["job-hunting-server<br/>(binary)"]
api["api<br/>(路由层 + 配置)"]
service["service<br/>(业务逻辑)"]
entity["entity<br/>(Sea-ORM 模型)"]
migration["migration<br/>(数据库迁移)"]
web["web<br/>(静态文件服务)"]
framework["framework<br/>(基础设施)"]
macros["macros / framework-macros<br/>(proc-macro)"]
build_metadata["build-metadata<br/>(构建元数据)"]
binary --> api
api --> framework
api --> service
api --> entity
api --> migration
api --> web
api --> macros
framework --> macros
framework --> build_metadata
| Crate | 说明 |
|---|---|
job-hunting-server | 二进制入口:CLI 解析、Tokio runtime、日志、信号处理 |
api | REST API 路由定义、路由组装、配置结构体、AppState |
service | 业务逻辑层:任务调度、数据同步、文件解析、Git 操作 |
entity | Sea-ORM 实体模型(自动生成 + 手动补充) |
migration | Sea-ORM 数据库迁移脚本 |
web | 使用 rust-embed 内嵌 server-ui 前端产物 |
framework | 共享基础设施:认证、错误处理、数据提取器、数据库连接、中间件 |
macros | proc-macro 工具(#[error] 错误码宏等) |
技术栈
- Web 框架: Axum 0.8
- 中间件: tower-http(CORS、timeout、body limit、tracing、compression)
- API 文档: utoipa-axum + Scalar
- ORM: Sea-ORM(PostgreSQL / SQLite)
- Auth: jsonwebtoken(HS256)+ bcrypt
- 配置: figment(TOML 文件 + 环境变量 + CLI 覆盖)
- ID 生成: xid
- 日志: tracing + tracing-subscriber(支持 console、文件、flamegraph、tokio-console)
- 测试: cucumber BDD + testcontainers
深入开发
架构概览
Crate 依赖关系
graph TD
binary["job-hunting-server<br/>(二进制入口)"]
api["api<br/>(路由 + 配置)"]
service["service<br/>(业务逻辑)"]
entity["entity<br/>(Sea-ORM 实体)"]
migration["migration<br/>(迁移)"]
web["web<br/>(静态文件)"]
framework["framework<br/>(基础设施)"]
macros["macros<br/>(proc-macro)"]
binary --> api
binary --> framework
api --> framework
api --> service
api --> entity
api --> migration
api --> web
framework --> macros
service --> entity
service --> framework
启动流程
sequenceDiagram
participant CLI as CLI / Config
participant Runtime as Tokio Runtime
participant Server as Server
participant DB as Database
participant Router as Axum Router
participant Scheduler as Scheduler
CLI ->> Runtime: 解析 CLI 参数,创建 Runtime
Runtime ->> Server: Server::new(args)
Server ->> Server: 加载配置(figment)
Server ->> Server: 初始化日志(tracing)
Runtime ->> DB: establish_connection(database_url)
DB -->> Runtime: DatabaseConnection
Runtime ->> DB: migration::Migrator::up()
DB -->> Runtime: 迁移完成
Runtime ->> Runtime: Jwt::init(auth_config)
par 并发启动
Runtime ->> Router: start_app(state)
Router ->> Router: create_router() + bind socket
and
Runtime ->> Scheduler: start_scheduler()
Scheduler ->> Scheduler: cron 循环执行任务
end
路由组装
所有 API 模块通过 create_routes(state: AppState) -> OpenApiRouter 导出路由,在 create_router() 中统一组装:
// api/src/lib.rs
pub fn create_router(state: AppState, ct: CancellationToken) -> Router {
let (router, api) = OpenApiRouter::with_openapi(ApiDoc::openapi())
// 嵌套各模块路由
.nest("/api", job::create_routes(state.clone()))
.nest("/api", company::create_routes(state.clone()))
.nest("/api", auth::create_routes(state.clone()))
// ... 更多模块
.split_for_parts();
router
// Scalar API 文档
.merge(Scalar::with_url("/docs", api))
// 静态文件
.route("/assets/{*file}", get(web::assets_handler))
// SPA fallback
.fallback(web::index_handler)
// 全局中间件
.layer((
TimeoutLayer::new(Duration::from_secs(300)),
DefaultBodyLimit::max(100 * 1024 * 1024),
TraceLayer::new_for_http(),
CorsLayer::permissive(),
))
}Handler 编写规范
每个 API handler 遵循统一模式:
// 1. 标签常量
const TAG: &str = "Company";
// 2. handler 函数
#[debug_handler]
#[utoipa::path(
post,
path = "/company",
tag = TAG,
security(("AccessToken" = [])),
request_body = CreateCompanyParam,
responses(
(status = 200, description = "创建成功", body = ApiResponse<Company>),
)
)]
async fn create(
State(AppState { conn, .. }): State<AppState>,
ValidJson(param): ValidJson<CreateCompanyParam>,
) -> ApiResult<ApiResponse<Company>> {
let result = CompanyService::create(&conn, param).await?;
Ok(ApiResponse::ok(result))
}
// 3. 路由导出
pub fn create_routes(state: AppState) -> OpenApiRouter {
OpenApiRouter::new()
.routes(routes!(create, update, search, detail, delete))
.with_state(state)
}关键约定:
#[debug_handler]提供编译期类型匹配错误提示#[utoipa::path]同时生成 Axum 路由和 OpenAPI 文档ValidJson<T>/ValidQuery<T>自动校验请求体/查询参数- 响应统一用
ApiResult<ApiResponse<T>>包装 routes!宏来自utoipa_axum,批量注册路由
中间件链
全局中间件按顺序应用:
| 中间件 | 说明 |
|---|---|
TimeoutLayer | 300 秒请求超时 |
DefaultBodyLimit | 100 MiB 请求体上限 |
TraceLayer | tracing 日志注入 |
CorsLayer | 允许所有来源跨域 |
模块级中间件:
JwtAuth— 通过route_layer(get_auth_layer())添加到需要认证的路由组CompressionLayer— 对静态资源路由启用 gzip 压缩
AppState
AppState 通过 Axum State 提取器在 handler 间共享:
pub struct AppState {
pub conn: DatabaseConnection,
pub auth_config: AuthConfig,
}ErrorCode 设计
使用教程
1. 定义错误码枚举
使用 #[error] 宏在 framework/src/error/ 下定义枚举,或在各业务模块中定义。
命名规则 - 枚举名称必须以 ErrorCode 结尾,前缀即为模块名
| 枚举名称 | 模块名 |
|---|---|
FrameworkErrorCode | framework |
UserErrorCode | user |
框架级错误码 - 定义在 framework/src/error/ 下
#[error]
pub enum FrameworkErrorCode {
// 3xx 框架错误: 参数校验失败、无效查询等
ValidationInvalid = 301001,
QueryInvalid = 301002,
}业务级错误码 - 定义在各业务模块中
#[error]
pub enum UserErrorCode {
// 5xx 业务错误
AccountNotFound = 503001,
OldPasswordIncorrect = 503002,
}默认 message - 从模块名 + 变体名自动生成(空格分隔)
| 模块名 | 变体名 | 默认消息 |
|---|---|---|
| user | AccountNotFound | "user account not found" |
| user | OldPasswordIncorrect | "user old password incorrect" |
| framework | ValidationInvalid | "framework validation invalid" |
自定义 message - 使用宏属性
#[error]
pub enum UserErrorCode {
#[error(message = "用户不存在")]
AccountNotFound = 503001,
}2. 在业务代码中使用
基本用法 - 使用 err! 宏自动注入调用位置
return Err(err!(UserErrorCode::AccountNotFound));
// message = "user account not found"
// 自动注入调用位置 (file:line)添加 extra_message
// 需要在 ErrorCode 定义中添加 with_extra 方法
return Err(err!(UserErrorCode::AccountNotFound.with_extra("user_id=123")));
// message = "user account not found"
// extra_message = "user_id=123"
// 自动注入调用位置使用 ? 运算符
let user = User::find_by_id(id).await?
.ok_or(err!(UserErrorCode::AccountNotFound))?;使用 with_extra
.ok_or(err!(UserErrorCode::AccountNotFound.with_extra("user_id not found")))?;3. API 响应格式
{
"code": 503001,
"message": "account not found"
}
-
在
error_tests!宏中添加新类型:error_tests! { FrameworkErrorCode, UserErrorCode, CompanyErrorCode, JobErrorCode, NewErrorCode, // 添加新类型 }
设计原理
错误码分类
| 分类 | 范围 | 说明 | 日志级别 | API 错误响应(StatusCode/Code/Message) |
|---|---|---|---|---|
| 1xxyyy | 101001-199999 | 底层错误,预留 | error | 500/内部错误 code/内部错误 |
| 2xxyyy | 201001-299999 | 第三方错误 | error | 500/内部错误 code/内部错误 |
| 3xxyyy | 301001-399999 | 框架错误:如参数校验失败 | warn | 500/内部错误 code/内部错误 |
| 4xxyyy | 401001-499999 | 关键业务错误:如多次登录错误,数据不完整 | warn | 500/内部错误 code/内部错误 |
| 5xxyyy | 501001-599999 | 业务错误 | info | 400/直出/直出 |
注意事项
- 登录错误: API 错误响应,按常规方式处理
- 参数校验失败: API 错误响应,按常规方式处理
编码规则
6 位数字:类别(1-5) + 模块(01-99) + 序号(001-999)
err! 宏
使用 err! 宏可以自动注入调用位置(file:line)。
原理
- 自动注入调用位置(
file!()+line!()) - 存储在
ApiError的file和line字段中
日志输出
[503001]account not found at src/user.rs:86
使用前提
- 在模块中引入 prelude:
use framework::prelude::*;- 开启 DEBUG 日志级别:
RUST_LOG=DEBUG
注意:文件和行号只在 DEBUG 级别下打印
核心逻辑与数据结构设计
数据同步流程
[!WIP]
数据同步流程以任务形式执行
流程:计算数据下载任务 -> 数据下载 -> 数据贮藏与合并
- 计算数据下载任务
- (task_data_plan,task_data_source_plan)task_plan <-> task,task_data_download
- 数据下载
- task,task_data_download <-> file,task,task_data_merge
- 数据贮藏与合并
- task,task_data_merge <-> task,task_data_merge,job_source,company_source,job_tag_source,company_tag_source,job,company,job_tag,company_tag
数据合并
sequenceDiagram participant out_data as 外部数据 participant logic as 数据处理器 participant source as 来源表 participant main as 主表 out_data ->> logic: 发送外部数据 logic ->> logic: 提取外部数据中的唯一标识(业务主键+uri)列表 logic ->> source: 根据唯一标识列表查询现存来源数据 source ->> logic: 返回现存来源数据 logic ->> logic: 去掉外部数据中重复的现存来源数据,得到去重外部数据 logic ->> source: 插入去重外部数据 source ->> logic: 插入外部去重数据成功 logic ->> logic: 提取去重外部数据的业务主键列表 logic ->> main: 根据业务主键列表查询现存主数据 main ->> logic: 返回现存主数据 logic ->> logic: 根据现存主数据和去重外部数据,计算出主数据插入列表和主数据更新列表 logic ->> main: 插入主数据插入列表 main ->> logic: 插入主数据插入列表成功 logic ->> main: 更新主数据更新列表 main ->> logic: 更新主数据更新列表成功
核心数据模型
URI 规范
参考:RFC 3986
- 第三方数据来源格式:
data://[username[@]]host/path - 本地文件导入数据来源格式:
data://[username[@]]system/[file_hash] - 界面新增或编辑数据来源格式:
data://[username[@]]system-ui/[version]/[file_hash]/[rfc3339]
字段说明:
username:数据贡献者/上传者标识
示例:
data://lastsunday@github.com/lastsunday/job-hunting-data/2026/03-03/job.zip
data://lastsunday@github.com/lastsunday/job-hunting-data/2024/12-20/company.zip
data://admin@system/c38036efd481b06a5b0a4292ac7dfbcfb93e9eb0d1c4de0aef0f4d685cf6b3a9
data://admin@system-ui/1/c38036efd481b06a5b0a4292ac7dfbcfb93e9eb0d1c4de0aef0f4d685cf6b3a9/2026-04-16T14:08:17+00:00
职位相关表
设计说明:
job_source:多渠道原始数据来源表,存储来自不同用户/渠道的原始数据job:标准化表,去重后的一手数据
---
title: Job ER
---
erDiagram
job_source{
id varchar(255) PK "编号"
job_id varchar(255) "职位编号"
platform varchar(255) "发布平台"
url varchar(255) "链接"
name varchar(255) "名称"
company_name varchar(255) "公司名"
location_name varchar(255) "地区"
address varchar(255) "地址"
longitude numeric(16_13) "经度"
latitude numeric(16_13) "纬度"
description text "描述"
degree_name varchar(255) "学历"
year int2 "所需经验"
salary_min numeric(12_2) "最低薪资"
salary_max numeric(12_2) "最高薪资"
salary_total_month int2 "几薪"
first_publish_datetime timestamptz "首次发布时间"
boss_name varchar(255) "招聘人名称"
boss_company_name varchar(255) "招聘公司"
boss_position varchar(255) "招聘者职位"
is_full_company_name bool "公司名是否为全称"
skill_tag text "技能标签: 逗号作为分隔符"
welfare_tag text "福利标签: 逗号作为分隔符"
first_scan_datetime timestamptz "首次扫描时间"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
job_source }|..|| job : "源自(最新)"
job {
id varchar(255) PK "职位编号"
platform varchar(255) "发布平台"
url varchar(255) "链接"
name varchar(255) "名称"
company_name varchar(255) "公司名"
location_name varchar(255) "地区"
address varchar(255) "地址"
longitude numeric(16_13) "经度"
latitude numeric(16_13) "纬度"
description text "描述"
degree_name varchar(255) "学历"
year int2 "所需经验"
salary_min numeric(12_2) "最低薪资"
salary_max numeric(12_2) "最高薪资"
salary_total_month int2 "几薪"
first_publish_datetime timestamptz "首次发布时间"
boss_name varchar(255) "招聘人名称"
boss_company_name varchar(255) "招聘公司"
boss_position varchar(255) "招聘者职位"
is_full_company_name bool "公司名是否为全称"
skill_tag text "技能标签: 逗号作为分隔符"
welfare_tag text "福利标签: 逗号作为分隔符"
first_scan_datetime timestamptz "首次扫描时间"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
公司相关表
设计说明:
company_source:多渠道原始数据来源表,存储来自不同用户/渠道的原始数据company:标准化表,去重后的一手数据
---
title: Company ER
---
erDiagram
company_source{
id varchar(255) PK "编号"
company_id varchar(255) "公司编号"
name varchar(255) "名称"
desc text "描述"
start_date timestamptz "成立时间"
status varchar(255) "经营状态"
legal_person varchar(255) "法人"
unified_code varchar(255) "统一社会信用代码"
web_site text "官网"
insurance_num int4 "社保人数"
self_risk int4 "自身风险数"
union_risk int4 "关联风险数"
address text "地址"
scope text "经营范围"
tax_no varchar(255) "纳税人识别号"
industry varchar(255) "所属行业"
license_number varchar(255) "工商注册号"
longitude numeric(16_13) "经度"
latitude numeric(16_13) "纬度"
source_url text "数据来源地址"
source_platform varchar(255) "数据来源平台"
source_record_id varchar(255) "数据来源记录编号"
source_refresh_datetime timestamptz "数据来源更新时间"
reg_capital_value numeric(17_2) "注册资本数值"
reg_capital_currency varchar(255) "注册资本货币"
paidin_capital_value numeric(17_2) "实缴资本数值"
paidin_capital_currency varchar(255) "实缴资本货币"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
company_source }|..|| company : "源自(最新)"
company{
id varchar(255) PK "公司编号"
name varchar(255) UK "名称"
desc text "描述"
start_date timestamptz "成立时间"
status varchar(255) "经营状态"
legal_person varchar(255) "法人"
unified_code varchar(255) "统一社会信用代码"
web_site text "官网"
insurance_num int4 "社保人数"
self_risk int4 "自身风险数"
union_risk int4 "关联风险数"
address text "地址"
scope text "经营范围"
tax_no varchar(255) "纳税人识别号"
industry varchar(255) "所属行业"
license_number varchar(255) "工商注册号"
longitude numeric(16_13) "经度"
latitude numeric(16_13) "纬度"
source_url text "数据来源地址"
source_platform varchar(255) "数据来源平台"
source_record_id varchar(255) "数据来源记录编号"
source_refresh_datetime timestamptz "数据来源更新时间"
reg_capital_value numeric(17_2) "注册资本数值"
reg_capital_currency varchar(255) "注册资本货币"
paidin_capital_value numeric(17_2) "实缴资本数值"
paidin_capital_currency varchar(255) "实缴资本货币"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
标签数据模型
---
title: Tag ER
---
erDiagram
tag{
id varchar(255) PK "编号"
name text "名称"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
tag ||--o{ job_tag_source: "关联"
job_tag_source{
id varchar(255) PK "编号"
job_id varchar(255) "职位编号"
tag_id varchar(255) "标签编号"
seq int4 "序号"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
tag ||--o{ company_tag_source: "关联"
company_tag_source{
id varchar(255) PK "编号"
company_id varchar(255) "公司编号"
company_name varchar(255) "公司名称"
tag_id varchar(255) "标签编号"
seq int4 "序号"
uri varchar(255) "来源"
publish_datetime timestamptz "数据发布时间"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
tag ||--o{ job_tag: "关联"
job ||--o{ job_tag: "关联"
job_tag_source }|..|| job_tag : "源自(最新)"
job_tag{
id varchar(255) PK "编号"
job_id varchar(255) "职位编号"
tag_id varchar(255) "标签编号"
seq int4 "序号"
uri varchar(255) "来源"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
tag ||--o{ company_tag: "关联"
company ||--o{ company_tag: "关联"
company_tag_source }|..|| company_tag : "源自(最新)"
company_tag{
id varchar(255) PK "编号"
company_id varchar(255) "公司编号"
company_name varchar(255) "公司名称"
tag_id varchar(255) "标签编号"
seq int4 "序号"
uri varchar(255) "来源"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
任务系统设计
任务关系图
设计说明:
task_data_plan/task_data_source_plan:用于生成task_plan的配置表,便于从界面上描述任务计划,实际参与任务生成的是task_plan
---
title: Task ER
---
erDiagram
task_plan{
id varchar(255) PK "编号"
type int4 "任务计划类型: 0: DATA_DOWNLOAD,1: METADATA_DOWNLOAD"
enable bool "开关"
config jsonb "配置"
cron varchar(255) "cron定时任务表达式"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task_plan ||..o| task : "触发"
task{
id varchar(255) PK "编号"
plan_id varchar(255) "任务计划编号"
type varchar(255) "任务类型"
data_id varchar(255) "任务编号"
status varchar(255) "状态"
error_reason text "错误原因"
cost_time int4 "耗时"
retry_count int4 "重试次数"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task_data_plan ||--|| task_plan: owns
task_data_plan{
id varchar(255) PK "编号"
plan_id varchar(255) "任务计划编号"
username varchar(255) "用户名"
repo_name varchar(255) "仓库名"
repo_type varchar(255) "仓库类型"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task_data_source_plan ||--|| task_plan: owns
task_data_source_plan{
id varchar(255) PK "编号"
plan_id varchar(255) "任务计划编号"
username varchar(255) "用户名"
repo_name varchar(255) "仓库名"
repo_type varchar(255) "仓库类型"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task ||--|| task_data_download: owns
task_data_download{
id varchar(255) PK "编号"
type varchar(255) "下载数据任务类型"
username varchar(255) "用户名"
repo_name varchar(255) "仓库名"
datetime timestamptz "时间"
config jsonb "配置"
data_id varchar(255) "文件编号"
seq int4 "序号"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task ||--|| task_data_merge: owns
task_data_merge{
id varchar(255) PK "编号"
type varchar(255) "合并数据任务类型"
username varchar(255) "用户名"
repo_name varchar(255) "仓库名"
datetime timestamptz "时间"
data_id varchar(255) "文件编号"
data_count int4 "合并后的数据总数"
config jsonb "配置"
data_page_num int4 "分页页码,控制批量合并的页索引"
data_page_size int4 "分页大小,控制每批合并的数据量"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
task_data_download ||..|| file : "生成"
task_data_merge ||..|| file : "读取"
file{
id varchar(255) PK "编号"
name varchar(255) "名称"
sha varchar(255) "sha"
content BLOB "内容"
size int8 "尺寸"
is_delete bool "是否删除"
create_datetime timestamptz "创建时间"
update_datetime timestamptz "更新时间"
}
任务类型
- JOB_DATA_DOWNLOAD
- JOB_DATA_STORAGE_AND_MERGE
- COMPANY_DATA_DOWNLOAD
- COMPANY_DATA_STORAGE_AND_MERGE
- COMPANY_TAG_DATA_DOWNLOAD
- COMPANY_TAG_DATA_STORAGE_AND_MERGE
- JOB_TAG_DATA_DOWNLOAD
- JOB_TAG_DATA_STORAGE_AND_MERGE
任务状态
状态值:
- READY:等待执行
- RUNNING:执行中
- CANCEL:已取消
- FINISHED:执行成功
- FINISHED_BUT_ERROR:执行完成但有错误
- ERROR:执行失败
---
title: Task state
---
stateDiagram-v2
[*] --> READY
READY --> RUNNING
READY --> CANCEL
RUNNING --> FINISHED
RUNNING --> FINISHED_BUT_ERROR
RUNNING --> ERROR
RUNNING --> CANCEL
FINISHED --> [*]
FINISHED_BUT_ERROR --> [*]
ERROR --> RUNNING
CANCEL --> [*]
状态转换说明:
- READY → RUNNING:任务被调度器领取
- READY → CANCEL:任务被取消
- RUNNING → FINISHED:任务执行成功
- RUNNING → FINISHED_BUT_ERROR:任务执行完成但有错误(如部分数据处理失败、超出重试次数)
- RUNNING → ERROR:任务执行失败(如网络异常、数据解析错误)
- RUNNING → CANCEL:任务执行中被取消
- ERROR → RUNNING:任务重试执行
任务编排
流程串联
流程一:计算数据下载任务
- 由
task_data_plan/task_data_source_plan生成task_plan task_plan触发创建task和task_data_download
流程二:数据下载
task+task_data_download执行下载- 下载完成后生成
file文件 - 下载任务完成后,根据预设的最大数据量生成多个合并任务,避免一次超大合并带来的性能问题
流程三:数据贮藏与合并
task+task_data_merge执行合并- 根据
data_page_num和data_page_size读取对应批次数据 - 合并流程:
- 写入 source 表(job_source, company_source, job_tag_source, company_tag_source),遇到重复数据则忽略
- 将最新数据写入标准化表(job, company, job_tag, company_tag)
data_count记录合并后的数据总数
失败重试策略
ERROR状态可触发重试,回到RUNNINGretry_count字段记录当前重试次数- 最大重试次数由系统配置设定
- 超出最大重试次数后状态置为
FINISHED_BUT_ERROR
配置与部署
配置加载机制
配置通过 figment 加载,支持多层来源,后者覆盖前者:
JH_CONFIG环境变量 → 指向一个 TOML 文件路径--config/-cCLI 参数 → 指定 TOML 配置文件路径JH_*环境变量 → 字段名转大写加JH_前缀,如database_url→JH_DATABASE_URL-O key=valueCLI 参数 → 直接覆盖(TOML 语法)
# 方式一:指定配置文件
./server --config=application-dev.toml
# 方式二:环境变量
JH_CONFIG=/etc/job-hunting/server.toml ./server
# 方式三:覆盖单个字段
./server -O database_url="postgres://localhost/mydb" -O port=8080
配置项参考
以下为 config 结构体中的全部字段,默认值即不做配置时的值。
Server
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
server_name | string | "localhost" | 服务器名称 |
address | string / string[] | ["127.0.0.1", "::1"] | 监听地址,支持多个 |
port | u16 / u16[] | 3000 | 监听端口 |
Database
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
database_url | string | "sqlite://db.sqlite?mode=rwc" | 数据库连接 URL(PostgreSQL 或 SQLite) |
Auth
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
auth_access_token_secret | string | "QLjJTeVblAlM47de" | Access Token 签名密钥 |
auth_access_token_expires_in | u32 | 28800 | Access Token 过期时间(秒) |
auth_refresh_token_secret | string | "N8lI0uitNzJl6vYK" | Refresh Token 签名密钥 |
auth_refresh_token_expires_in | u32 | 15897600 | Refresh Token 过期时间(秒) |
auth_audience | string | "audience" | JWT audience |
auth_issuer | string | "issuer" | JWT issuer |
auth_client_id | string | "d1aicsr57dijo7h963ig" | 客户端 ID |
auth_client_secret | string | "ujTgh2lEQYy0PXhK" | 客户端密钥 |
生产环境必须修改:
auth_access_token_secret、auth_refresh_token_secret
Task
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
history_file_max_size | u64 | 5368709120 | 历史文件最大总大小(字节,默认 5 GiB) |
Logging
| 字段 | 类型 | 默认值 | 说明 |
|---|---|---|---|
log_console_enabled | bool | true | 启用控制台日志 |
log_console_level | string | "info" | 控制台日志级别(trace/debug/info/warn/error) |
log_console_format | string | "text" | 控制台输出格式(text/json/compact/pretty) |
log_file_enabled | bool | false | 启用文件日志 |
log_file_level | string | "info" | 文件日志级别 |
log_file_format | string | "json" | 文件输出格式 |
log_file_directory | string | "./logs" | 日志目录 |
log_file_name | string | "server" | 日志文件名前缀 |
log_file_max_files | u32 | 10 | 最多保留的日志文件数 |
log_file_rotation | string | "daily" | 日志轮转策略(daily/hourly/never) |
log_tokio_console_enabled | bool | false | 启用 tokio-console(性能分析) |
log_flame_enabled | bool | false | 启用火焰图输出 |
log_flame_directory | string | "./flame" | 火焰图输出目录 |
完整配置示例
server_name = "job-hunting"
address = "0.0.0.0"
port = 3000
database_url = "postgres://user:password@localhost:5432/job_hunting"
# 生产环境务必修改以下两项
auth_access_token_secret = "your-long-secret-string"
auth_access_token_expires_in = 28800
auth_refresh_token_secret = "your-another-secret-string"
auth_refresh_token_expires_in = 15897600
log_console_enabled = true
log_console_level = "info"
log_file_enabled = true
log_file_level = "debug"
log_file_directory = "/var/log/job-hunting"
log_file_rotation = "daily"
数据库迁移
迁移由 Sea-ORM 管理,在服务器启动时自动执行,无需手动干预:
// api/src/lib.rs - api::start() 中
migration::Migrator::up(&conn, None).await?;也可手动执行迁移 CLI:
# 在 migration 目录下
cargo run -- up
迁移文件位于 migration/src/,按时间命名:
m20260000_000000_init.rs— 初始建表m20260605_000001_add_indexes.rs— 索引补充
Docker 部署
构建镜像
# 交叉编译二进制(由 CI 负责)
# 构建 Docker 镜像
docker build -t job-hunting-server -f apps/server/Dockerfile .
Dockerfile(简化版)
FROM alpine:3.20.2
WORKDIR /app
COPY target/release/job-hunting-server /app/server
EXPOSE 3000
CMD ["./server"]
docker-compose(PostgreSQL 本地开发)
项目中提供了 docker-compose.yml,仅包含 PostgreSQL 服务:
cd apps/server
docker compose up -d # 启动 PostgreSQL
修改配置指向本地 PostgreSQL:
./server -O database_url="postgres://postgres:changeme@127.0.0.1:5432/postgres"
运行时控制
CLI 参数
./server --help
# 可选参数:
# -c, --config <FILE> 指定配置文件(可多次指定)
# -O <KEY=VALUE> 覆盖配置项(TOML 语法)
信号(Linux/macOS)
| 信号 | 行为 |
|---|---|
SIGINT | 优雅关闭 |
SIGTERM / SIGQUIT | 立即关闭 |
SIGUSR1 | 重新加载日志配置 |
SIGUSR2 | 循环切换控制台日志级别 |
moon 任务
| 命令 | 说明 |
|---|---|
moon run server:build | 编译二进制 |
moon run server:dev | 开发模式运行(使用 application-dev.toml) |
moon run server:run | 正式运行(使用 application.toml) |
moon run server:test | 运行测试 |
moon run server:lint | 运行 clippy |
moon run server:format | 格式检查 |
moon run server:bump | 版本升级 + 生成 CHANGELOG |
测试
测试架构
测试分布在三个 crate 中,按层次划分:
| Crate | 测试类型 | 工具 | 位置 |
|---|---|---|---|
framework | 纯单元测试 | #[cfg(test)] 内联 | src/*.rs |
service | 业务逻辑集成测试 | testcontainers + SQLite | service/tests/ |
api | API BDD 测试 + 接口集成测试 | cucumber + tower::oneshot | api/tests/ |
graph TD
subgraph "api/tests/"
BDD["Cucumber BDD<br/>(feature 文件 + step 定义)"]
INT["HTTP 集成测试<br/>(oneshot 发请求)"]
end
subgraph "service/tests/"
SVC["业务逻辑测试<br/>(DAO / Git / 任务流)"]
end
subgraph "framework/src/"
UNIT["纯单元测试<br/>(工具函数)"]
end
BDD -->|调用 handlers| Router["Axum Router<br/>(完整路由栈)"]
INT -->|调用 handlers| Router
SVC -->|直接操作| DB["Sea-ORM Connection<br/>(SQLite in-memory)"]
Cucumber BDD 测试
BDD 测试是 API 层的主要测试方式,使用 cucumber crate。
目录结构
api/tests/
├── common/
│ └── mod.rs # 测试辅助函数:HTTP 客户端、DB 初始化
├── features/ # Gherkin 场景文件
│ ├── auth/auth.feature
│ ├── company/company.feature
│ └── job/get_info/search.feature
├── feature_auth_test.rs # Auth step 定义
├── feature_company_test.rs # Company step 定义
├── feature_job_test.rs # Job search step 定义
├── company_test.rs # 纯单元测试(CSV 转换)
└── index_test.rs # 冒烟测试
World 结构体
每个 feature 文件对应一个 World 结构体,实现 cucumber::World trait:
#[derive(Debug, Default, cucumber::World)]
struct TestWorld {
// 数据库连接
conn: Option<DatabaseConnection>,
// 当前登录用户的 token
access_token: Option<String>,
// 某场景下的状态(如创建的公司 ID)
company_id: Option<String>,
// ...
}Feature 文件示例
Feature: Company CRUD
Background:
Given insert tables
Scenario: Create company
Given access_token without token
When I create the #companyName company
Then I should see company created
Scenario: Search companies
Given access_token without token
And company #companyName created
When I search companies without params
Then I should see company #companyName in the search results
Step 定义示例
#[given(expr = "access_token {word} token")]
async fn setup_token(world: &mut TestWorld, token_type: String) {
// 根据 token_type 设置 world.access_token
match token_type.as_str() {
"without" => world.access_token = None,
"with" => {
// 登录获取 token
let result = login(&world.conn, "root", "root").await;
world.access_token = Some(result.access_token);
}
_ => unreachable!(),
}
}
#[when(expr = "I create the {string} company")]
async fn create_company(world: &mut TestWorld, name: String) {
use common::post_json_with_token;
let resp = post_json_with_token(
&world.app, "/api/company", &create_params(&name), world.access_token.as_deref()
).await;
let body = common::response_to_json(resp).await;
world.company_id = Some(common::get_from_value(&body, "data.id"));
}
#[then(expr = "I should see company {string} in the search results")]
async fn check_company_in_results(world: &mut TestWorld, name: String) {
let resp = get_json_with_token(
&world.app, "/api/company/search?name={name}", world.access_token.as_deref()
).await;
let body = common::response_to_json(resp).await;
let items = common::get_json_paging_result_items(&body);
assert!(items.iter().any(|i| i["name"] == name));
}场景执行入口
每个 BDD 测试文件有一个 #[tokio::test] 入口:
#[tokio::test]
async fn main() {
TestWorld::cucumber()
.before(|_feature, _rule, _scenario, world| {
// 每个场景前执行:初始化数据库、组装 Router
Box::pin(async {
let (container, conn) = common::setup_database().await;
world.conn = Some(conn.clone());
world.app = Some(create_test_router(conn).await);
world.container = container;
})
})
.after(|_feature, _rule, _scenario, world| {
// 每个场景后执行:清理数据库
Box::pin(async {
common::tear_down(world.container.take()).await;
})
})
.run("tests/features/company/company.feature")
.await;
}运行 BDD 测试
# 运行所有 API 测试(含 BDD 和集成测试)
cargo test --package job-hunting-server
# 仅运行 API crate 的测试
moon run server:test
数据库:测试隔离
每个测试场景获得独立的 SQLite in-memory 数据库,通过 setup_database() 创建:
pub async fn setup_database() -> (Option<ContainerAsync<Postgres>>, DatabaseConnection) {
// 当前使用 SQLite in-memory(快速、隔离)
let container = None;
let conn = framework::database::establish_connection("sqlite::memory:")
.await
.unwrap();
// 运行全部迁移
migration::Migrator::up(&conn, None).await.unwrap();
(container, conn)
}设计预留了切换到 PostgreSQL 的能力:取消注释 testcontainers 部分即可,
Option<ContainerAsync<Postgres>>保证了兼容。
测试辅助工具
api/tests/common/mod.rs 提供了一套 HTTP 测试工具函数,通过 tower::ServiceExt::oneshot 直接向 Axum Router 发请求(不走 TCP 网络):
| 函数 | 说明 |
|---|---|
setup_database() | 初始化 SQLite 内存库 + 运行迁移 |
tear_down() | 如需则停止 testcontainers 容器 |
response_to_json() | Response<Body> → serde_json::Value |
get_json_result() | 从 API 响应中提取 data 字段 |
get_json_paging_result_items() | 从分页响应中提取 data.items |
get_from_value() | 从 JSON Value 中按类型提取字段 |
post_json() | POST JSON body |
post_json_with_token() | POST JSON body + Bearer token |
get_json() / get_json_with_token() | GET + 可选 token |
put_json() / put_json_with_token() | PUT + 可选 token |
delete_json() / delete_json_with_token() | DELETE + 可选 token |
服务层测试
service/tests/ 下的测试直接操作 Sea-ORM 连接和业务逻辑:
dao_test.rs: 实体 CRUD、分页查询file_parser_test.rs: Excel 文件解析、表头校验import_job_test.rs: 从 Excel 行导入职位数据import_company_test.rs: 从 Excel 行导入公司数据task_test.rs: 完整的下载+合并任务流程scheduler_test.rs: 任务计划调度 + 任务队列消费git_test.rs/git_lite_test.rs: Git 操作(需 Gitea testcontainers)
服务层测试也提供了一套公共工具(service/tests/common/mod.rs),包括:
setup_gitea_with_test_data()— 启动 Gitea 容器并推送测试 fixture 数据create_test_file_map()— 映射测试资源文件
测试用 Fixture 数据
service/tests/resources/data/
├── job-v0.zip / job-v1.zip # 职位数据
├── company-v0.zip / company-v1.zip / company-v2.zip # 公司数据
├── job-v1.xlsx # 职位 Excel
└── company-v2.xlsx # 公司 Excel
新增测试场景
新增 API BDD 场景
- 在
features/对应子目录下编写.feature文件 - 在
feature_*_test.rs中添加#[given]/#[when]/#[then]step 定义 - 在 step 定义中使用
common::*工具函数发送 HTTP 请求、提取响应
新增服务层测试
- 在
service/tests/下新建_test.rs文件 - 使用
common::setup_database()初始化数据库 - 直接调用
servicecrate 中的函数并断言结果
数据源
数据源仓库说明
- 仓库目录结构
├── 2025 //年份,格式YYYY
│ └── 07-01 //月日,格式MM-DD
│ └── 深圳避雷公司.zip //数据文件,格式xxx.zip(包含文件xxx.xlsx)备注:zip文件和xlsx文件的文件名必须相同
├── metadata.json //源数据,包含数据源元数据,可用的数据源列表
- metadata.json 文件格式
{
"data": {
"source": [
{
"name": "" //数据源名称
"config": {
"taskTypeList": [
{
"name": "", //名称
"type": "COMPANY_COMMENT_DATA_DOWNLOAD", //固定值,代表公司评论数据类型
"emotion": "NEGATIVE", //情感导向,负面:NEGATIVE,积极:POSITIVE,正常:其他值
"fileName": "深圳避雷公司", //数据文件名
"description": "", //描述
"retentionDay": 3650 //数据保留时间,单位:天
}
]
},
"repoType": "GITHUB", //固定值
"reponame": "", //仓库名
"username": "", //仓库用户名
"description": "" //数据源描述
}
]
},
"icon":"", //元数据图标,格式为svg,注意转移字符
"name": "", //元数据名称
"type": "GIT_METADATA", //固定值,GIT元数据类型
"config": {
"config": {
"url": "", //元数据git仓库地址,以http或https开头的地址
"filePath": "metadata.json" //元数据文件名,一般取metadata.json
}
},
"enable": true, //是否开启
"description": "", //元数据描述
"autoUpdateEnable": true //是否自动更新元数据
}
-
公司评论数据文件格式
公司 评论 xxxx yyyy 备注:
- 第一行的标题必须保留,插件会以标题来标识字段列的数据
- 公司:可以同时填写多家公司,换行隔开
- 公司或评论为空的行将被跳过
-
Q&A
-
如何更新数据? 根据仓库目录结构,新建年月日目录,将整理后的数据文件zip 文件上传到新建的年月日目录里即可
-
如何快速测试文件格式是否正确 打开插件后台页面 ->系统 ->数据管理 ->公司评论数据导入
如果能正常导入 xlsx 文件,则代表该文件正常(当前不支持导入 zip 文件)
-
如何使用?
-
新增元数据:打开插件后台页面 ->数据源 ->元数据 ->从网络导入
1.从网络导入,填入 metadata.json 的访问地址: https://github.com/用户名/仓库名/raw/refs/heads/main/metadata.json
-
添加数据源: 打开插件后台页面 ->数据源 ->列表 ->搜寻数据源 ->选中新增的元数据 ->选中并添加数据源
-
-
数据同步的逻辑是怎样的? 插件会遍历整个仓库的年月日目录,根据 metadata.json 的规则进行数据的增量同步,公司评论信息采取 散列(公司名+评论)作为唯一标识进行去重逻辑。
-
Commit Message
<type>[optional scope]: <description>
[optional body]
[optional footer(s)]
提交说明包含了下面的结构化元素,以向类库使用者表明其意图:
fix: 类型 为 fix 的提交表示在代码库中修复了一个 bug(这和语义化版本中的 PATCH 相对应)。
feat: 类型 为 feat 的提交表示在代码库中新增了一个功能(这和语义化版本中的 MINOR 相对应)。
BREAKING CHANGE: 在脚注中包含 BREAKING CHANGE: 或 <类型>(范围) 后面有一个 ! 的提交,表示引入了破坏性 API 变更(这和语义化版本中的 MAJOR 相对应)。 破坏性变更可以是任意 类型 提交的一部分。
除 fix: 和 feat: 之外,也可以使用其它提交 类型 ,例如 @commitlint/config-conventional(基于 Angular 约定)中推荐的 build:、chore:、 ci:、docs:、style:、refactor:、perf:、test:,等等。
build: 用于修改项目构建系统,例如修改依赖库、外部接口或者升级 Node 版本等;
chore: 用于对非业务性代码进行修改,例如修改构建流程或者工具配置等;
ci: 用于修改持续集成流程,例如修改 Travis、Jenkins 等工作流配置;
docs: 用于修改文档,例如修改 README 文件、API 文档等;
style: 用于修改代码的样式,例如调整缩进、空格、空行等;
refactor: 用于重构代码,例如修改代码结构、变量名、函数名等但不修改功能逻辑;
perf: 用于优化性能,例如提升代码的性能、减少内存占用等;
test: 用于修改测试用例,例如添加、删除、修改代码的测试用例等。
脚注中除了 BREAKING CHANGE: <description> ,其它条目应该采用类似 git trailer format 这样的惯例。
其它提交类型在约定式提交规范中并没有强制限制,并且在语义化版本中没有隐式影响(除非它们包含 BREAKING CHANGE)。 可以为提交类型添加一个围在圆括号内的范围,以为其提供额外的上下文信息。例如 feat(parser): adds ability to parse arrays.。
特别地:
bump: v1.1.0,代表发布版本
Version
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
主版本号:当你做了不兼容的 API 修改,
次版本号:当你做了向下兼容的功能性新增,
修订号:当你做了向下兼容的问题修正。
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
Reference
- https://keepachangelog.com/zh-CN/1.1.0/
- https://github.com/angular/angular/blob/main/CONTRIBUTING.md#-commit-message-format
- https://www.conventionalcommits.org/zh-hans/v1.0.0/
- https://semver.org/lang/zh-CN/
auto_explain
db = new PGlite(`opfs-ahp://${JOB_DB_PATH}`, {
extensions: { auto_explain },
debug:1,
});
await db.exec(`
LOAD 'auto_explain';
SET auto_explain.log_min_duration = '0';
SET auto_explain.log_analyze = 'true';
`);
打开offscreen的console,可看到详细的分析日志
Transaction
Chrome Extension下的持久层事务问题(Transaction)
- 当前采用PGLite,其事务的调用采用异步调用下的在回调函数里进行,如
await pg.transaction(async (tx) => {
await tx.query(
'INSERT INTO test (name) VALUES ('$1');',
[ 'test' ]
);
return await tx.query('SELECT * FROM test;');
});
- Chrome Extension的调用链为
ContentScript(或SidePanel) -> Background -> OffScreen -> WebWorker
而持久层(即PGLite)是在WebWorker进行调用,而运行逻辑部份是放在Background或ContentScript(或SidePanel)里,这样会出现一个问题,怎样使得逻辑的调用链处在事务的回调函数里?
可能的解决方案
- 传递tx对象
伪代码:
let idAndTxMap = new Map();
let idAndTxPromiseResolveReject = new Map()
async function startTransaction(){
await pg.transaction(async (tx) => {
let id = genId();
idAndTxMap.set(id,tx);
postMessage(message,id);
return new Promise((resolve,reject)=>{
idAndTxPromiseResolveReject.set(id,{resolve,reject});
});
});
}
async function endTransaction(id){
idAndTxPromiseResolveReject.get(id).resolve();
}
async function update(param,{transactionId=null}={}){
let connection = idAndTxMap.get(transactionId)??await getDb();
connection.query("update....",param);
}
async main(){
let id = await startTransaction();
update(param,{transactionId:id})
await endTransaction(id);
}
- 将逻辑都放到WebWorker里
选择的解决方案
- 选择将逻辑都放到WebWorker里。
Dump
数据库备份
https://github.com/electric-sql/pglite/tree/main/packages/pglite-tools
这里有pgDump的工具,但整合后报错(pg_dump failed with exit code 1),不能正常导出
- 导出
package.json
"@electric-sql/pglite-tools": "^0.2.2",
wxt.config.ts
copyFileSync(resolve(srcDir, "node_modules", "@electric-sql", "pglite-tools", "dist", "pg_dump.wasm"), resolve(outDir, "assets", "pg_dump.wasm"));
database.js
import { PGlite } from '@electric-sql/pglite'
import { pgDump } from '@electric-sql/pglite-tools/pg_dump'
const pg = await PGlite.create()
// Create a table and insert some data
await pg.exec(`
CREATE TABLE test (
id SERIAL PRIMARY KEY,
name TEXT
);
`)
await pg.exec(`
INSERT INTO test (name) VALUES ('test');
`)
// Dump the database to a file
const dump = await pgDump({ pg })
- 导入
Data Share Plan 数据共享计划
文档版本:2024-10-10
背景
招聘网站展示给应聘者的岗位存在某些问题
- 职位并不是最新的,有可能是挂职几个月的,一页展示的只有大概三分之一是最近的
- 部分职位因为使用某种手段,使其展示的优先级往上靠
- 某些招聘网站没有提供按职位发布时间进行排序的功能
- 招聘网站提供的职位搜索条件较少,一般只通过职位关键字来进行搜索
基于上述的原因,实现数据共享计划并结合 JobHutting 内置的职位偏好功能是部分痛点的解决方案
数据字段
职位数据字段
职位自编号
发布平台
职位访问地址
职位
公司
公司是否为全称
地区
地址
经度
纬度
职位描述
学历
所需经验
最低薪资
最高薪资
首次发布时间
招聘人
招聘公司
招聘者职位
首次扫描日期
记录更新日期
公司数据字段
公司
公司描述
成立时间
经营状态
法人
统一社会信用代码
官网
社保人数
自身风险数
关联风险数
地址
经营范围
纳税人识别号
所属行业
工商注册号
经度
纬度
数据来源地址
数据来源平台
数据来源记录编号
数据来源更新时间
公司标签数据字段
公司
标签
数据流向
官方数据流(数据上传)
招聘网站 -> JobHunting Extension -> Git(个人GitHub仓库)
共享数据流(数据下载)
共享数据仓库列表 -> Git(个人GitHub仓库) -> JobHunting Extension
数据提交流程
最多每天提交一次,插件启动时开启定时检查任务
查询仓库最近一次提交时间
提交的记录的范围条件:记录更新时间 < 今天0点0分 和记录更新时间 >= 最近一次提交时间
备注:针对公司标签,现在是全量提交
提交的目录
提交时间(YYYY)
提交时间(MM-DD)
job.zip
company.zip
company_tag.zip
数据获取和同步流程
1. 查询仓库60天内的记录
2. 下载60天内缺失的数据文件
3. 根据数据文件进行数据同步
4. 针对不同类型数据进行处理
职位数据
如果是新数据
新增记录
如果是重复数据
根据创建时间来处理,并且需要处理公司名全称问题
公司数据
如果是新数据
新增记录
如果是重复数据
根据数据来源更新时间来处理
公司标签数据
如果是新数据
新增记录
如果是重复数据
合并标签
关键组件及行为
相关表
task 任务表
id 编号
type 任务类型
data_id 数据编号
status 任务状态
error_reason 异常原因
cost_time 最近一次任务执行耗时
retry_count 重试次数
create_datetime 创建时间
update_datetime 更新时间
task_data_upload 任务数据表(上传)
id 编号
type 任务类型
username 用户名
reponame 仓库名
start_datetime 数据开始时间
end_datetime 数据结束时间
data_count 数据总量
create_datetime 创建时间
update_datetime 更新时间
task_data_download 任务数据表(下载)
id 编号
type 任务类型
username 用户名
reponame 仓库名
datetime 文件日期
create_datetime 创建时间
update_datetime 更新时间
file 文件表
id 编号
name 文件名
sha 散列值
encoding 文件内容编码,
content 文件内容,
size 文件尺寸,
type 类型(当前只有file)
create_datetime 创建时间
update_datetime 更新时间
task_data_merge 任务数据表(数据合并)
id 编号
type 任务类型
username 用户名
reponame 仓库名
datetime 文件日期
data_id 文件编号
data_count 数据总量
create_datetime 创建时间
update_datetime 更新时间
data_share_partner 数据共享伙伴信息表
id 编号
username 用户名
reponame 仓库名
repo_type 仓库类型(当前只有GITHUB)
create_datetime 创建时间
update_datetime 更新时间
附表:
任务类型
职位数据上传:TASK_TYPE_JOB_DATA_UPLOAD
公司数据上传:TASK_TYPE_COMPANY_DATA_UPLOAD
公司标签数据上传:TASK_TYPE_COMPANY_TAG_DATA_UPLOAD
职位数据下载:TASK_TYPE_JOB_DATA_DOWNLOAD
公司数据下载:TASK_TYPE_COMPANY_DATA_DOWNLOAD
公司标签数据下载:TASK_TYPE_COMPANY_TAG_DATA_DOWNLOAD
职位数据合并:TASK_TYPE_JOB_DATA_MERGE
公司数据合并:TASK_TYPE_COMPANY_DATA_MERGE
公司标签数据合并:TASK_TYPE_COMPANY_TAG_DATA_MERGE
状态
准备:TASK_STATUS_READY
运行中:TASK_STATUS_RUNNING
完成:TASK_STATUS_FINISHED
异常完成:TASK_STATUS_FINISHED_BUT_ERROR
错误:TASK_STATUS_ERROR
取消:TASK_STATUS_CANCEL
数据存储目录结构
提交时间(YYYY)
提交时间(MM-DD)
job.zip
company.zip
company_tag.zip
GitHub
仓库的建立
所需权限:"Administration" repository permissions (write)
https://docs.github.com/en/rest/repos/repos?apiVersion=2022-11-28#create-a-repository-for-the-authenticated-user
/user/repos
仓库目录的提交&数据文件的提交
所需权限:"Contents" repository permissions (write)
https://docs.github.com/en/rest/repos/contents?apiVersion=2022-11-28#create-or-update-file-contents
/repos/{owner}/{repo}/contents/{path}
仓库目录的查询&仓库文件的下载
所需权限:无
特别事项:This API has an upper limit of 1,000 files for a directory. If you need to retrieve more files,
https://docs.github.com/en/rest/repos/contents?apiVersion=2022-11-28#get-repository-content
/repos/{owner}/{repo}/contents/{path}
FAQ
1. 报错 No more file handles available in the pool
如果在 Linux 下,请使用命令 ulimit -n 检查 soft file descriptor 的值,一般默认为 1024 或 2048,请设定一个较高的值如 9001
免责声明
1. 项目目的与性质
本项目(以下简称“本项目”)是作为一个技术研究与学习工具而创建的,旨在探索和学习网络数据采集技术。本项目专注于招聘平台的数据爬取与分析技术研究,旨在提供给学习者和研究者作为技术交流之用。
2. 法律合规性声明
本项目开发者(以下简称“开发者”)郑重提醒用户在下载、安装和使用本项目时,严格遵守中华人民共和国相关法律法规,包括但不限于《中华人民共和国网络安全法》、《中华人民共和国反间谍法》等所有适用的国家法律和政策。用户应自行承担一切因使用本项目而可能引起的法律责任。
3. 使用目的限制
本项目严禁用于任何非法目的或非学习、非研究的商业行为。本项目不得用于任何形式的非法侵入他人计算机系统,不得用于任何侵犯他人知识产权或其他合法权益的行为。用户应保证其使用本项目的目的纯属个人学习和技术研究,不得用于任何形式的非法活动。
4. 免责声明
开发者已尽最大努力确保本项目的正当性及安全性,但不对用户使用本项目可能引起的任何形式的直接或间接损失承担责任。包括但不限于由于使用本项目而导致的任何数据丢失、设备损坏、法律诉讼等。
5. 知识产权声明
本项目的知识产权归开发者所有。本项目受到著作权法和国际著作权条约以及其他知识产权法律和条约的保护。用户在遵守本声明及相关法律法规的前提下,可以下载和使用本项目。
6. 最终解释权
关于本项目的最终解释权归开发者所有。开发者保留随时更改或更新本免责声明的权利,恕不另行通知。